Lossless Compression with Asymmetric Numeral Systems
During my undergraduate days, one of the most interesting courses I took was on coding and compression. Here was a course that combined algorithms, probability and secret messages, what's not to like? 1 I ended up not going down that career path, at least partially because communications systems had its heyday around the 2000s with companies like Nortel and Blackberry and its predecessors (some like to joke that all the major theoretical breakthroughs were done by Shannon and his discovery of information theory around 1950). Fortunately, I eventually wound up studying industrial applications of classical AI techniques and then machine learning, which has really grown like crazy in the last 10 years or so. Which is exactly why I was so surprised that a new and better method of lossless compression was developed in 2009 after I finished my undergraduate degree when I was well into my PhD. It's a bit mind boggling that something as well-studied as entropy-based lossless compression still had (have?) totally new methods to discover, but I digress.
In this post, I'm going to write about a relatively new entropy based encoding method called Asymmetrical Numeral Systems (ANS) developed by Jaroslaw (Jarek) Duda [2]. If you've ever heard of Arithmetic Coding (probably best known for its use in JPEG compression), ANS runs in a very similar vein. It can generate codes that are close to the theoretical compression limit (similar to Arithmetic coding) but is much more efficient. It's been used in modern compression algorithms since 2014 including compressors developed by Facebook, Apple and Google [3]. As usual, I'm going to go over some background, some math, some examples to help with intuition, and finally some experiments with a toy ANS implementation I wrote. I hope you're as excited as I am, let's begin!
Background: Data Coding and Compression
Most modern digital communication is done via transmitting bits (i.e. 0/1 values) with the goals of both reliability and efficiency. A symbol is unit of information that is transmitted, which can be the bits itself or a higher level concept represented by a sequence of bits (e.g. "a", "b", "c", "d" etc.). An alphabet is the set of all symbols that you can transmit. A message is a sequence of symbols that you want to transmit.
Often you will want to code a message (such as a file) for storage or transmission on a communication channel by specifying some rules on how to transform it into another form. The usual reasons why you want to code a message is compression (fewer bits), redundancy (error correction/detection), or encryption (confidentiality). For compression, we generally have two main approaches: lossy and lossless. In lossy schemes, you drop some non-essential details in the message (think image compression) to trade-off a greater reduction in size. This trick is used extensively in things like image (e.g. JPEG) or audio (e.g. MP3) compression. Lossless schemes on the other hand aim to retain the exact message reducing the file size by exploiting some statistical redundancies in the data. We're mainly talking about lossless compression schemes today.
Lossless schemes come in many forms such as Run Length Encoding, Lempel-Ziv compression, Huffman coding, and Arithmetic coding, which probably constitute the most popular ones (aside from ANS, which we'll be discussing today). Most of the ones above work by reading one or more symbols (think bytes) from the data stream and replacing it with some compact bit representation. For example, in Huffman Coding, the most frequent symbol is replaced with a single bit, or Run Length Encoding, which replaces a repeated sequence of a character by the character and how many times it repeats. In both these examples, it works on a subset of the sequence and replaces them. The other variant which both Arithmetic coding and Asymmetrical Numeral Systems fall under is where then entire message is encoded as a single number (the smaller or less precise the number, the shorter the message). This allows you to get closer to the theoretical compression limit.
Speaking of theoretical compression limits, according to Shannon's source coding theorem the theoretical limit you can (losslessly) compress data is equal to its entropy. In other words, the average number of bits per symbol of your message cannot be smaller than:
where it's presumed that you know the \(p_i\) distribution of each of your \(n\) symbols ahead of time. Note that the logarithm is base 2, which naturally allows us to talk in terms of "bits". I wrote some details on how to think about entropy in my previous post on maximum entropy distributions so I won't go into much detail now.
Example 1: Entropy of a Discrete Probability Distribution
Imagine we have an alphabet with 3 symbols: \(\{a, b, c\}\). Let random variable \(X\) represent the probability of seeing a symbol in a message, and is given by the distribution: \(p_a = \frac{4}{7}, p_b=\frac{2}{7}, p_c=\frac{1}{7}\).
The entropy and minimum average number of bits per symbol we can achieve for messages with this distribution (according the the source coding theorem) is:
Contrast that to naively encoding each symbol using 2-bits (vs. 1.3788), for example, representing "a" as 00, "b" as 01, and "c" as 10 (leaving 11 unassigned).
This can also be contrasted to assuming that we had a uniform distribution (\(p_a=p_b=p_c=\frac{1}{3}\)), which would yield us an entropy of \(H(X)=-3\cdot\frac{1}{3}log_2(\frac{1}{3}) = 1.5850\) vs. 1.3788 with a more skewed distribution. This shows a larger idea that uniform distributions are the "hardest" to compress (i.e. have the highest entropy) because you can't really exploit any asymmetry in the symbol distribution -- all of them are equally likely.
One class of lossless compression schemes is called entropy encoders and they exploit the estimated statistical properties of your message in order to get pretty close to the theoretical compression limit. Huffman coding, Arithmetic coding, and Asymmetric Numeral Systems all are entropy encoders.
Finally, the metric we'll be using is compression ratio, defined as:
Asymmetric Numeral Systems
Asymmetric Numeral Systems (ANS) is a entropy encoding method used in data compression developed by Jaroslaw Duda [2] in 2009. It has a really simple idea: take a message as a sequence of symbols and encode it as a single natural number \(x\). If \(x\) is small, it requires fewer bits to represent; if \(x\) is large, then it requires more bits to represent. Or to think about it the other way, if I can exploit the statistical properties of my message so that: (a) the most likely messages get mapped to small natural numbers, and (b) the least likely messages get mapped to larger natural numbers, then I will have achieved good compression. Let's explore this idea a bit more.
Encoding a Binary String to a Natural Number
First off, let's discuss how we can even map a sequence of symbols to a natural number. We can start with the simplest case: a sequence of binary symbols (0s and 1s). We all know how to convert a binary string to a natural number, but let's break it down into its fundamental parts. We are particularly interested in how to incrementally build up to the natural number by reading one bit at a time.
Suppose we have already converted some binary string \(b_1 b_2 b_3 \ldots b_i\) (\(b_1\) being the most significant digit) into a natural number \(x_i\) via the typical method of converting (unsigned) binary numbers to natural numbers. If we get another another binary digit \(b_{i+1}\), we want to derive a coding function such that \(x_{i+1} = C(x_i, b_{i+1})\) generates the natural number representation of \(b_1 b_2 b_3 \ldots b_{i+1}\). If you remember your discrete math courses, it should really just be multiplying the original number by 2 (shifting up a digit in binary), and then adding the new binary digit, which is just:
If we start with \(x_0=0\), you can see that we'll be able to convert any binary string iteratively (from MSB to LSB) to its natural number representation. Inversely, we can convert from any natural number to iteratively recover both the binary digit \(b_{i+1}\) and the next resulting natural number without that digit using the following decoding function:
Nothing really new here but let's make a few observations:
We shouldn't start with \(x_0=0\), because we won't be able to distinguish between "0", "00", "000" etc. because they all map to \(0\). Instead, let's start at \(x_0=1\), which effectively adds a leading "1" to each message we generate but now "0" and "00" can be distinguished as ("10" and "100").
Let's look at how we're using \(b_{i+1}\). In Equation 3, if \(b_{i+1}\) is odd, then we add 1, else if even we add 0. In Equation 4, we're doing the reverse, if the number \(x_{i+1}\) is odd, we know we can recover a "1", else when even, we recover an "0". We'll use this idea in order to extend to more complicated cases.
Finally, the encoding using Equations 3 and 4 are optimal if we have a uniform distribution of "0"s and "1"s (i.e. \(p_0=p_1=\frac{1}{2}\)). Notice that the entropy \(H(x) = -2 \cdot \frac{1}{2}\log_2(\frac{1}{2}) = 1\), which results in 1 bit per binary digit, which is exactly what these equations generate (if you exclude the fact that we start at 1).
The last two points are relevant because it gives us a hint as to how we might extend this to non-uniform binary messages. Our encoding is optimal because we were able to spread the evens and odds (over any given range) in proportion to their probability. We'll explore this idea a bit more in the next section.
Example 2: Encoding a Binary String to/from a Natural Number
Using Equation 3 and 4, let's convert binary string \(b_1 b_2 b_3 b_4 b_5 = 10011\) to a natural number. Starting with \(x_0=1\), we have:
To recover our original message, we can use \(D(x_{i+1})\):
Notice that we recovered our original message in the reverse order. The number of bits needed to represent our natural number is \(\lceil \log_2(51) \rceil = 6\) bits, which is just 1 bit above our ideal entropy of 5 bits (assuming a uniform distribution).
Redefining the Odds (and Evens)
Let's think about why the naive encoding in the previous section might result in an optimal code for a uniform distribution. For one, it spreads even and odd numbers (binary strings ending in "0"'s and "1"'s respectively) uniformly across any natural number range. This kind of makes sense since they are uniformly distributed. What's the analogy for a non-uniform distribution?
If we were going to map a non-uniform distribution with \(p_1=p < 1-p = p_0\), then we would want the more frequent symbol (0 in this case) to appear more often in any given mapped natural number range. More precisely, we would want even numbers to be mapped in a given range roughly \(\frac{1-p}{p}\) more often than odd numbers. Or stated another way, in a given mapped natural number range from \([1, N]\) we would want to see roughly \(N\cdot p\) evens and \(N\cdot (1-p)\) odds. This is the right intuition but doesn't really show how it might generate an optimal code. Let's work backwards from an optimal compression scheme and figure out what we would need.
We are trying to define the encoding function \(x_{i+1} = C(x_i, b_{i+1})\) (similarly to Equation 3) such that each incremental bit generates the minimal amount of entropy. Assuming that \(x_i\) has \(\log_2 (x_i)\) bits of information, and we want to encode \(b_{i+1}\) optimally with \(-\log_2(p_{b_{i+1}})\) bits, we have (with a bit of abuse of entropy notation):
Therefore, if we can define \(C(x_i, b_{i+1}) \approx \frac{x_i}{p_{b_{i+1}}}\) then we will have achieved an optimal code! Let's try to understand what this mapping means.
From Equation 8, if we are starting at some \(x_i\) and get a new bit \(b_{i+1}=1\) (an odd number), then \(x_{i+1}\approx\frac{x_i}{p}\). But we know \(x_i\) can be any natural number, so this implies that odd numbers will be placed at (roughly), \(\frac{1}{p}, \frac{2}{p}, \frac{3}{p}, \ldots\) intervals for any given natural number. This also means, we'll see an odd number (roughly) every \(\frac{1}{p}\) natural numbers. But if we take a closer look, this is precisely the condition of having roughly \(N\cdot p\) for the first \(N\) natural numbers (\(\text{# of Odds} = N / \frac{1}{p} = N\cdot p\)). Similarly, we'll see even numbers (roughly) every \(\frac{1}{1-p}\), which also means we'll see (roughly) \(N \cdot (1-p)\) in the first \(N\) natural numbers. So our intuition does lead us towards the solution of an optimal code after all!
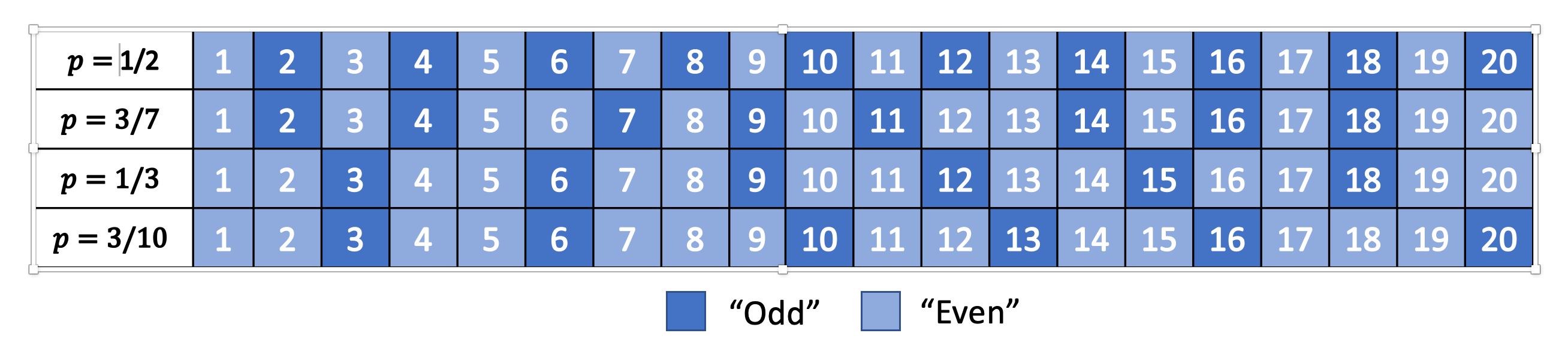
Figure 1: Distribution of Evens and Odds for Various :math:`p`
Thinking about this code a bit differently, we are essentially redefining the frequency of evens and odds with this new mapping. We can see this more clearly in Figure 1. For different values of \(p\), we can see a repeating pattern of where the evens and odds fall. When \(p=1/2\), we see an alternating pattern (never mind that \(2\) is mapped to an odd, this is an unimportant quirk of the implementation) as we usually expect. However, when we go to non-uniform distributions, we can see repeating but non-alternating patterns. One thing you may notice is that the above equations are in \(\mathbb{R}\) but we need them to mapped to natural numbers! Figure 1 implicitly does some of the required rounding and we'll see more of that in the implementations below.
In summary:
A binary message encoded and decoded to a single natural number.
Using this method, we can build an entropy encoder by defining a mapping of even and odd binary numbers (those ending in "1'/"0"s) in proportion to their probabilities (\(p, 1-p\)) in a message.
We can incrementally generate this number bit by bit by using a coding function \(x_{i+1} = C(x_i, b_{i+1})\) (decoding function \((x_i, b_{i+1}) = D(x_{i+1})\)) that will iteratively generate a mapped natural number from (to) the previous mapped number and the next bit.
If we can guarantee our coding function \(C(x_i, b_{i+1}) \approx \frac{x_i}{p_{b_{i+1}}}\) then we will have achieved an optimal code.
Uniform Binary Variant (uABS)
Without loss of generality, let's use a binary alphabet with odds ending in "1" and evens ending in "0", and \(p_1 = p < 1-p = p_0\) (odds are always less frequent than evens). We know we want approximately \(N\cdot p\) odd numbers mapped in the first \(N\) mapped natural numbers. Since we have to have a non-fractional number of odds, let's pick \(\lceil N \cdot p \rceil\) odds in the first \(N\) mapped natural numbers. From this, we get this relationship for any given \(N\) and \(N+1\) (try to validate it against Figure 1):
Another way to think about it is: if we're at \(N\) and we've filled our \(\lceil N \cdot p\rceil\) odd number "quota" then we don't need to see another odd at \(N+1\) (the \(0\) case). Conversely, if going to \(N+1\) makes it so we're behind our odd number "quota" then we should make sure that we map an odd at \(N\) (the \(1\) case).
Now here's the tricky part: what coding function \(x_{i+1} = C(x_i, b_{i+1})\) satisfies Equation 9 (where \(x_i\) is our mapped natural number)? It turns out this one does:
I couldn't quite figure out a sensible derivation of why this particular function works but it's probably non-trivial. The main problem is that we're working with natural numbers, so dealing with floor and ceil operators is tricky. Additionally, Equation 9 kind of looks like a some kind of difference equation, which are generally very difficult to solve. However, I did manage to prove that Equation 10 is consistent with Equation 9. See Appendix A for the proof.
Using Equation 10, we can now code any binary message using the same method we used in the previous section with Equation 3: iteratively applying Equation 10 one bit at a time. The matching decoding function is essentially the reverse calculation:
The decoding of a bit is calculated exactly as we have designed it in Equation 9, and depending on which bit was decoded, we perform the reverse calculation of Equation 10. For the \(b_{i+1} = 0\) case, it may not look like the reverse calculation but the math should work out (haven't proven it, but my implementation works). In the end, the equations to encode/decode are straight forward but the logic of arriving at them is far from it.
Example 3: Encoding a Binary String to/from a Natural Number using uABS
Using the same binary string as Example 2, \(b_1 b_2 b_3 b_4 b_5 = 10011\), let's encode it using uABS but with \(p=\frac{7}{10}\) (recall we assume that \(p=p_1 < p_0=1-p\)). Using Equation 10 and starting with \(x_0=1\), we get:
Decoding can be applied in a similar way with Equation 11, which recovers our original message of "10011" (but in reverse order):
Another popular way to visualize this is using a tabular method in Figure 2. In the top row, we have the same visualization of evens/odds as Figure 1 for \(p=\frac{3}{10}\), which is essentially \(C(x_i, b_{i+1})\). In the second and third row, it shows which numbers are mapped to evens/odds and counts the number of "slots" of evens/odds we have see up to that point. So for \(C(x_i, b_{i+1})=3\), it's mapped to the first odd "slot", and for \(C(x_i, b_{i+1})=26\), it's mapped to the eighth odd "slot". The same thing happens on the even side.
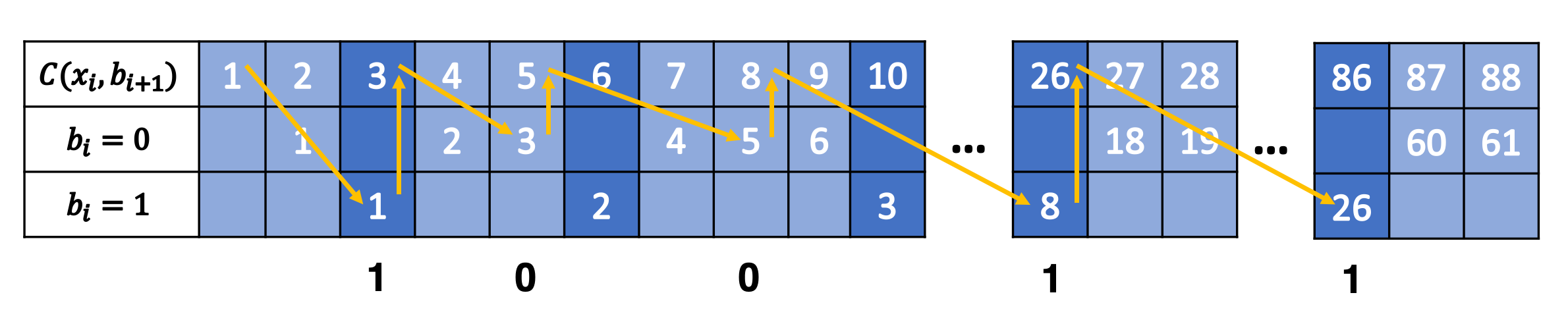
Figure 2: Tabular Visualization of uABS Encoding
This turns out to be precisely what Equation 10 is doing: for any given \(x_i\) it's trying to find the next even/odd "slot" to put \(x_{i+1}\) in. The yellow lines trace out what an encoding for "10011" would look like. Our current number \(x_i\) along with the incoming bit \(b_{i+1}\) defines which "slot" we should go in (the diagonal arrows), and Equation 10 calculates the next natural number associated with it (the "up" arrows). Decoding would follow a similar process but in reverse.
Range Variant (rANS)
We saw that uABS works on a binary alphabet, but we can also apply the same concept to an alphabet of any size (with some modifications). The first thing to notice is that that the argument from Equation 8 works (more or less) with any alphabet, not just binary ones (just replace the bit \(b_{i+1}\) with symbol \(s_{i+1}\)). That is, adding an incremental symbol (instead of a bit) should only increase the total entropy of the message by the entropy of that symbol. Equation 8 would only need to reference symbol and the same logic would work.
Another problem are those pesky real numbers. Theoretically, we can have arbitrary real numbers for the probability distribution of our alphabet. We "magically" found a nice formula in Equation 10/11 that encodes/decodes any arbitrary \(p\), but in the case of a larger alphabet, it's a bit tougher. Instead, a restriction that we'll place is that we'll quantize the probability distribution in \(2^n\) chunks. So \(p_s\approx \frac{f_s}{2^n}\), where \(f_s\) is a natural number. This quantization of the probability distribution, simplifies things for us by allowing us to have a simpler and more efficient coding/decoding function (although it's not clear to me if it's possible to do it without quantization).
Instead of our previous idea of evens and odds, what we'll be doing is extending this idea and "coloring" each number. So for an alphabet of size 3, we might color things red, green and blue. Figure 3 shows a few examples with this alphabet with \(n=3\) quantization for a few different distributions (this is analogous to Figure 1).
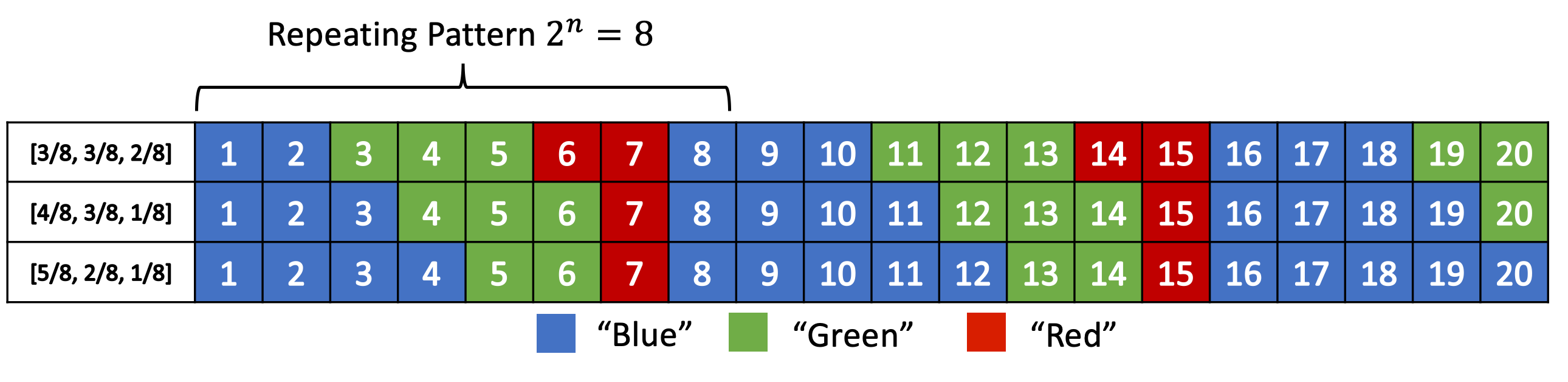
Figure 3: Distribution of "blue", "green" and "red" symbols
So how does it work? It's not too far off from uABS, we use the following equations to encode/decode:
Where \(CDF[s] := f_0 + f_1 + \ldots + f_{s-1}\), essentially the cumulative distribution function for a given ordering of the symbols. You'll notice that since we've quantized the distribution in terms of powers of 2, we can replace the multiplications, divisions and modulo with left shifting, right shifting and logical masking, respectively, which makes this much more efficient computationally.
The intuition for Equation 14-16 isn't too far from from uABS: for a given \(N\), we want to maintain the property that we roughly see \(N\cdot p_s = N \cdot \frac{f_s}{2^n}\) of symbols \(s\). Looking at Equation 14, we can see how it accomplishes this:
\(\lfloor \frac{x_i}{f_s} \rfloor \cdot 2^n\): finds the right \(2^n\) range (recall that we have a repeating pattern every \(2^n\) natural numbers). If \(f_s\) is small, say \(f_s=1\), then it only appears once every \(2^n\) range. If \(f_s\) is large, then we would expect to see \(f_s\) numbers mapped to every \(2^n\) range.
\(CDF[s]\) finds the offset within the \(2^n\) range for the current symbol \(s\) -- all \(s\) symbols will be grouped together within this range starting here.
\((x_i \bmod f_s)\) finds the precise location within this sub-range (which has precisely \(f_s\) spaces allocated for it).
The decoding is basically just the reverse operation of the encoding.
Since we maintain this repeating pattern, we implicitly are maintaining the property that we'll see \(x_i \cdot p_s\) "\(s\)" symbols within the first \(x_i\) natural numbers.
Example 4: Encoding a Ternary String to/from a Natural Number using rANS
Using the alphabet ['a', 'b', 'c'] with quantization \(n=3\) and distribution \([f_a, f_b, f_c]=[5, 2, 1]\) (\(CDF[s] = [0, 5, 7, 8]\)), let's encode the string "abc". We need to start with \(x_0=8\) or we won't be able to encode repeated values of 'a' (similar to how we start uABS at 1). In fact, we just need to start with the \(\max f_s\) but to be safe, we'll use \(2^n\). Using Equation 14:
Decoding, works similarly using Equation 15-16:
We can build the same table as Figure 2 except we'll have four rows: for \(C(x_i, s_{i+1}), a, b, c\). Building the table is left as an exercise for the reader :)
Note about the starting value of \(x_0\)
In Example 4, we started on \(x_0=2^n\). This is because if we didn't, we could get into the situation where we couldn't distinguish certain repetitions of strings such as: [a, aa, aaa], for example. Using Example 4, let's see what we'd get starting with \(x_0=1\):
As you can see we get nowhere fast. The reason is that the first term always rounds down, resulting in the exact same value. Similarly, the second term always resolves the same thing (since 'a' is the first symbol in our ordering), and the third term as well.
I think (haven't really proven it) that the safest option is to have \(\max f_s\) as your starting value. This will ensure that the first term will always be >= 0, resulting in a different number than you started with. To be safe, \(2^n > \max f_s\), which is just a bit nicer. In some sense, we're "wasting" the initial numbers here starting \(x_0\) larger but it's necessary in order to encode repeated strings and handle these corner cases.
Another way you could go about it, is that do a fixed mapping for the first \(2^n\) numbers (a base case of sorts), and then from there you can apply the formula. I didn't try this but I think that this is also possible.
Renormalization
The astute reader may have already been wondering how this can work in practice. It works great when you only have a message of length five or so, but what about a 1 MB file? If we use a 1-byte=256-length alphabet, we could potentially be getting a number on the order of \(2^{1000000n}\) over this 1M-length string. Surely no integer type will be able to efficiently handle that! It turns out there is a simple trick to ensure that \(x^i \in [2^M, 2^{2M} - 1]\).
The idea is that during encoding once \(x_i\) gets too big, we simply write out the lower \(M\) bits to ensure it stays between \([2^M, 2^{2M} - 1]\) (e.g. \(M=16\) bits). Similarly, during decoding, if \(x_i\) is too small, shift the current number up and read in \(M\) bits into the lower bits. As long as you take care to make sure each operation is symmetric, it should allow you to always play with a number that fits within an integer type.
Listing 1: Encoding and Decoding rANS Python Pseudocode with Renormalization
Listing 1 shows the Python pseudo code for rANS encoding and decoding with renormalization. Notice that we use Equation 14-16 but with more efficient bit-wise operations.
Other variants
As you can imagine, there are numerous variants of the above algorithms/concepts, especially as it relates to efficient implementations. One of the most practical is one called tANS or the tabled variant. In this variation, we build a finite state machine (i.e. table) to pre-compute all the calculations we would have done in rANS. This has a bit more upfront cost but will make the encoding/decoding much faster without the need for multiplications.
Another extension of tANS is the ability to encrypt the message directly in the tANS algorithm. Since we're building a table, we don't really need to maintain Equation 14-16 but rather can pick any repeating pattern. So instead of the typical rANS repeating pattern, we can scramble it based on some random number. See [1] for more details.
Implementation Details
I implemented some toy versions of uABS and rANS in Python which you can find on my Github. Surprisingly, it was a bit trickier than I thought due to a few gotchas. Here are some notes for implementing uABS:
Python's integer type is theoretically unlimited but I used some numpy functions, which do have a limited range (64-bit integer). You can see this when using uABS with large binary strings, particularly with close to uniform distributions, where the code encodes/decodes string incorrectly.
The other "gotcha" is that with uABS, we are actually (sort of) dealing with real numbers, which is a poor match for floating point data types. Python's floating point type definitely has limited precision, so the usual problems of being not represent real numbers exactly become a problem. Especially when we need to apply ceil/floor where a 0.000001 difference is meaningful. To hack around this, I simply just wrapped everything in Python's Decimal type.
Finally, to ensure that the smaller \(p\) was always mapped to the "1", I had do some swapping of the characters and probabilities.
For rANS, it was a bit easier, except for the renormalization, where I had to play around a bit:
I decided to simplify my life, I would just directly take the frequencies (\(f_s\)) along with the quantization bits (\(n\)) instead of introducing errors quantizing things myself.
As mentioned above, I kept having errors until I figured out that \(x_0\) needed to start at a large enough value. With renormalization, I start it at \(x_0=2^M-1\) since we want \(x_i \in [2^M, 2^{2M}-1]\). Turns out you need to have minus one there or else you get into a corner case where the decoding logic stops decoding early (or at least my implementation did).
The other thing I had to "figure out" was the BOUND in Listing 1. I initially thought it was simply just \(2^{2M}-1\) but I was wrong. In [1], they reference a bound[s] variable that is never defined, so I had to reverse engineer it. I'm almost positive there is a better way to do it than what I have in Listing 1, but I think my way is the most straight forward.
In the decoding, there is a step where you have to lookup which symbol was decoded. I simply used numpy.argmax, which I presume does a linear search. Apparently, this is one place where you can do something smarter but I wasn't too interested in this part.
I didn't have to do any of the funny wrapping using Decimal that I did with uABS because of the quantization to \(n\) bits. There is still a division and call to floor() but since we're dealing with integers in the division, the chances of causing issues is pretty small I think (at least I haven't seen it yet).
Finally, none of my toy implementation, nor the compression values are quite realistic because you also need to include the encoding of the probability distribution itself! Something that you would surely include as metadata in a file. However, if we're compression a file that's relatively big, this constant amount of data should be negligible.
Experiments
The setup for uABS and rANS experiments were roughly the same. First, a random strings of varying length was generated based on the alphabet, distribution and quantization bits (for rANS). Next, the compression algorithm is run against the string and the original message size, ideal (Shannon limit) size, and actual size were measured or calculated. For each uABS experiment, each setting was run with 100 different strings and averaged, while for rANS it was run 50 times and averaged.
Figure 4 shows the results for uABS where "actual_ratio" stands for compression ratio. First off, more skewed distributions (lower \(p\)) result in higher compression. This is sensible because we can exploit the fact that odd numbers appear much more often. Next, it's clear that as the message length increase, we get a better compression ratio (closer to ideal). This expected as the asymptotic behavior of the code starts paying off. Interesting, for more skewed distributions (\(p=0.01\)), it takes much longer message lengths for us to get close to the theoretical limit. We would probably need a message length of \(N * 1 / p\) to start approaching that limit. Unfortunately, since I didn't implement renormalization, I couldn't push the message length too much further since the numbers got too big.
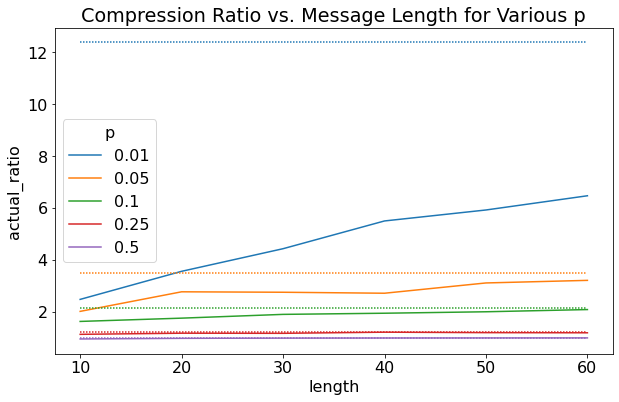
Figure 4: Experimental Results for uABS (dashed lines are the ideal compression ratio)
Figure 5 show the first set of results for rANS. Here we used an 256 character alphabet (8-bits = 1byte) with 15 quantization bits and 24 renormalization bits. Figure 5 shows various distributions for varying message lengths. Uniform is self explanatory, power_X are normalized power distributions with exponent \(X\). We see the same pattern of more skewed distributions having higher compression and reaching close to theoretical limit with longer message sizes.
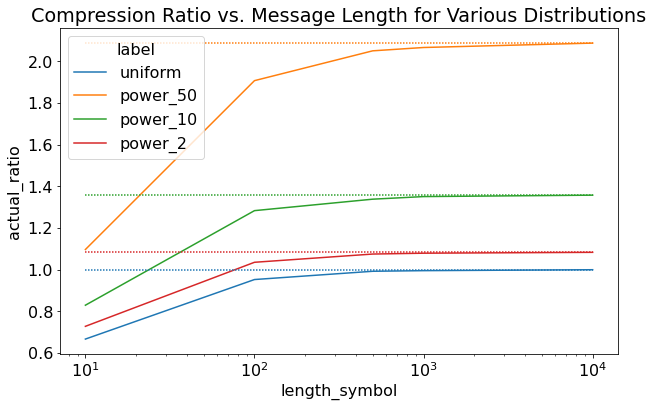
Figure 5: Experimental Results for rANS varying message length and distribution (dashed lines are the ideal compression ratio)
Figure 6 shows an ablation study for rANS on quantization bits. I held constant power_50 distribution with message length 1000 and varied quantization bits and renormalization bits. renormalization_bits = add_renorm_bits + quantization_bits. We can see that more precise quantization yields better compression, as expected. It can get closer to the actual power_50 distribution instead of being a coarse approximation. Varying the renormalization bits relative to quantization doesn't seem to have much effect in terms of compression ratio (I suspect there's more to it here but I didn't want to spend too much time investigating it).
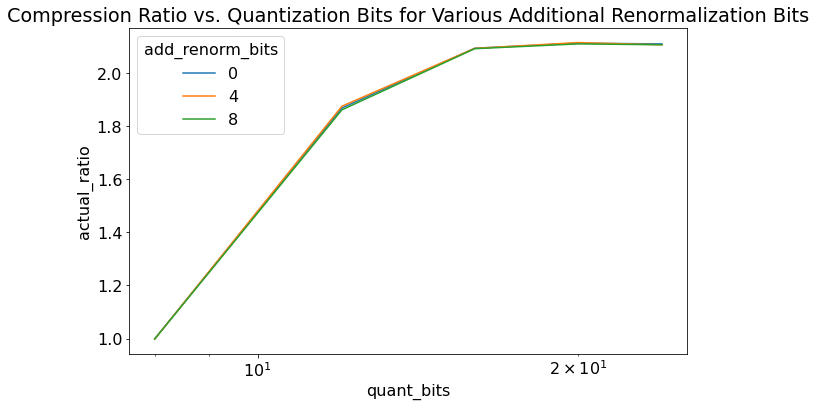
Figure 6: Experimental Results for rANS varying quantization bits and renormalization bits
Conclusion
Well this post was definitely another tangent that I went off on. In fact, the post I actually wanted to write was ML related but I got side tracked trying to understand ANS. It just was so interesting that I thought I should learn it more in depth and write a post on it. I keep trying to make more time for writing on this blog but I always seem to have more and more things keeping me busy professionally and personally (which is a good thing!). Anyways, look out for a future post where I will make reference to ANS. Thanks for reading!
References
[1] "Lecture I: data compression ... data encoding", Jaroslaw Duda, Nokia Krakow, http://ww2.ii.uj.edu.pl/~smieja/teaching/ti/3a.pdf
[2] "Asymmetric numeral systems", Jarek Duda, https://arxiv.org/abs/0902.0271
[3] Wikipedia: https://en.wikipedia.org/wiki/Asymmetric_numeral_systems
Appendix A: Proof of uABS Coding Function
(As an aside: I spent longer than I'd like to admit trying to figure out this proof. It turns out that trying to prove things involving floor and ceil functions wasn't so obvious for a computer engineer by training. I tried looking up a bunch of identities and going in circles using modulo notation without much success. It was only after going back to the definition of the floor/ceil operators, did I figure out the proof below. There's probably some lesson here about first principles but I'll let you take what you want from this story.)
Let's start out by assuming that \(p = \frac{a}{b}\) can be represented as a rational number for some relatively prime \(a, b \in \mathbb{Z}^{+}\). Practically, we're working with non-infinite precision, so it's not too big of a stretch. To verify that Equation 10 is consistent with Equation 9, we'll use substitution and show that the two equations are consistent.
Case 1: N is odd
Re-write Equation 9 odd case:
Substitute Equation A.1 into Equation 9 (where we're taking \(N=x_{i+1}\)):
Case 2: N is even
Substitute Equation 9 and A.3 into Equation 9:
Now looking at the last line and looking at the expression in the ceil function, we can see that:
So \((- \frac{i}{b-a} - 1)\cdot \frac{a}{b} > -1\) (and obviously \(< 0\)), therefore Equation A.4 resolves to \(- \lceil (- \frac{i}{b-a} - 1) \cdot \frac{a}{b} \rceil = 0\) as required.
Notes
- 1
-
I actually liked most of the communication theory courses, it was interesting to learn the basics of how wired/wireless signals are transmitted and how they could be modelled using math.