Importance Sampling and Estimating Marginal Likelihood in Variational Autoencoders
It took a while but I'm back! This post is kind of a digression (which seems to happen a lot) along my journey of learning more about probabilistic generative models. There's so much in ML that you can't help learning a lot of random things along the way. That's why it's interesting, right?
Today's topic is importance sampling. It's a really old idea that you may have learned in a statistics class (I didn't) but somehow is useful in deep learning, what's old is new right? How this is relevant to the discussion is that when we have a large latent variable model (e.g. a variational autoencoder), we want to be able to efficiently estimate the marginal likelihood given data. The marginal likelihood is kind of taken for granted in the experiments of some VAE papers when comparing different models. I was curious how it was actually computed and it took me down this rabbit hole. Turns out it's actually pretty interesting! As usual, I'll have a mix of background material, examples, math and code to build some intuition around this topic. Enjoy!
A Brief Review of Monte Carlo Simulation
Monte Carlo simulation methods are a broad class of algorithms that use repeated sampling (hence Monte Carlo like the casino in Monaco) to obtain a numerical result. These techniques are useful when we cannot explicitly compute the end result either because we don't know how or it's too inefficient. The simplest example is computing an expectation when the closed form result is unavailable but we can sample from the underlying distribution (there are many others examples, see the Wiki page). In this case, we can take our usual equation for expectation and approximate it by a summation. Given random variable \(X\) with density function \(p(x)\), distributed according to \(Q\), we have:
This is a simple restatement of the law of large numbers. To make this a bit more useful, we don't just want the expectation of a single random variable, instead we usually have some (deterministic) function of a vector of random variables. Using the same idea as Equation 1, we have:
where all of the quantities are now vectors and \(f\) is a deterministic function. For more well behaved smaller problems, we can get a reasonably good estimate of this expectation with \(\frac{1}{\sqrt{n}}\) convergence (by the central limit theorem). That is, quadrupling the number of points halves the error. Let's take a look at an example.
Example 1: Computing the expected number of times to miss a project deadline (source [1])
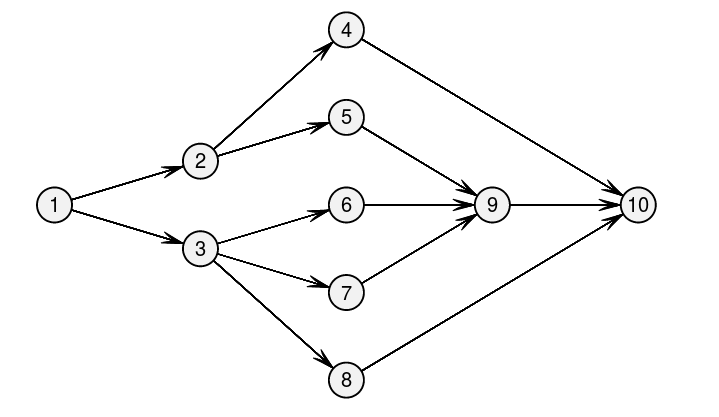
Figure 1: The graph of task dependencies (source [1]).
Imagine, we're running a project with 10 distinct steps. The project has dependencies shown in Figure 1. Further, the mean time to complete each task is listed in Table 1.
Task j |
Predecessors |
Duration (days) |
|---|---|---|
1 |
None |
4 |
2 |
1 |
4 |
3 |
1 |
2 |
4 |
2 |
5 |
5 |
2 |
2 |
6 |
3 |
3 |
7 |
3 |
2 |
8 |
3 |
3 |
9 |
5,6,7 |
2 |
10 |
4, 8, 9 |
2 |
If we add up the critical path in the graph we get a completion time of 15 days. But estimating each task completion time as a point estimate is not very useful when we want to understand if the project is at risk of delays. So let's model each task as an independent random exponential distribution with mean according to the duration of the task. When we simulate this, our mean time to completion is around \(18.2\) days. (It's not exactly the 15 days we might expect by adding up the critical path because the sum of two exponentials is not a simple exponential distribution.) This example along with the one below is shown in this: notebook.
Now suppose that there is a large penalty if we exceed 70 days. Figure 2 shows the proportion of times we exceed 70 days over several Monte Carlo simulations with different number of trials.
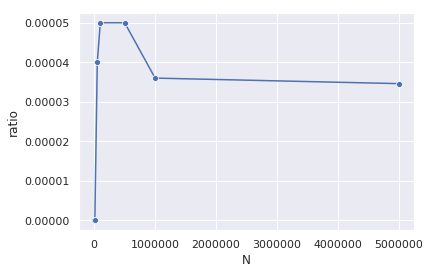
Figure 2: Estimated probability of occurrence of tasks exceeding 70 days using Monte Carlo simulation.
You can see we over- and under-estimate the number of times we exceed 70 days when N is low. For N={1000, 10000}, we in fact get 0 trials; for N={500k, 100k, 500k} it looks like we've overestimating it. Only when we approach 1,000,000 do we get close to the true estimate. Of course, this rare occurrence would give us problems in straight forward Monte Carlo simulations, the question is can we do better?
Importance Sampling
It turns out there is a more efficient way to do Monte Carlo simulation and it's called importance sampling. Let's suppose we want to compute the expected value of some random variable: \(E(f({\bf X})) = \int_{\mathcal{D}} f({\bf x})p({\bf x}) d{\bf x}\), where \(f({\bf x})\) is some deterministic function, \(p({\bf x})\) is some probability density function on \(\mathbb{R}^{d}\). For some other density function \(q({\bf x})\) over the same support, we have:
We simply just multiplied the numerator and denominator by \(q({\bf x})\) to get Equation 3. The interesting thing to notice here is that the expectation has suddenly switched from being with respect to \(p({\bf x})\) to \(q({\bf x})\). The extra ratio between the two densities (called the likelihood ratio) is used to compensate for using \(q({\bf x})\) to sample instead of \(p({\bf x})\). The distribution \(q\) is called the importance distribution and \(p\) is called the nominal distribution. There are some additional requirements on \(q\), such as it has to be positive everywhere \(f({\bf x})p({\bf x}) \neq 0\) is positive, or else you would be dividing by 0.
This leads us directly to the importance sampling estimate, which is simply just a restatement of Equation 2 with the expectation from Equation 3:
The main idea here is that if we pick \(q\) carefully, we might have a more efficient method. The simplest case is what we saw in Example 1, for long-tail events, we can sample an alternate distribution that puts more density further out, allowing us to keep the Monte Carlo sampling reasonable. The only caveat is that since we're using a different distribution than the actual, we have to adjust, which is where the extra likelihood ratio comes in.
So why go through all this trouble? The big result is this theorem:
Theorem 1:
Let \(\mu=E_p(f({\bf X}))\), then \(E_q(\hat{\mu_q}) = \mu\) and \(Var_q(\hat{\mu_q}) = \frac{\sigma^2_q}{n}\) where
This theorem essentially states that we'll converge to the same value as vanilla Monte Carlo sampling but potentially with a tighter variance (Equation 5) depending on how we pick \(Q\). Equation 5 follow directly from the fact that \(\hat{\mu_q}\) is a mean of iid variables and the fact that the underlying variable is our \(fp/q\) (to get the second expression in Equation 5, try multiplying \(q({\bf x})\) on the top and bottom).
We can see a desirable \(q\) has a few properties:
From the first expression in Equation 5, we want \(q\) to be close to \(fp\) so the variance is low (since \(\mu = \int f({\bf x})p({\bf x}) d{\bf x}\)). In general, we want it to have a similar shape; peaks and tails where we have peaks and tails in the original distribution.
From the second expression, we can also see that the variance is magnified when \(q\) is close to 0. Again, we need to ensure \(q\) has density in similar places as \(p\).
For standard distributions, we can usually take something with a similar shape, or the same distribution but with slightly modified parameters. It's kind of both an art and a science type of thing. For example, for Gaussian's we would use a t-distribution, and for exponentials we might shift the parameter around. Note that it's not guaranteed to actually improve your sampling efficiency though. However, if you do some careful selection of the importance distribution it can be quite efficient. There are a bunch of diagnostics to check whether or not the importance distribution matches. Check out [1] for a more detailed treatment.
Example 2 (Continuing from Example 1): Computing the expected number of times to miss a project deadline (source [1])
We can use importance sampling to drastically reduce the number of simulations that we have to do. Our importance distributions will be exponential just like our nominal distributions but with different parameters. Our new importance distributions will be exponentials with mean \(\lambda_j\), call it \(T_j \sim Exp(\lambda_j)\). We'll call the original parameters for our exponentials as \(\theta_j\) (durations listed in Table 1). We'll call the total duration of all tasks \(D_i = \sum_{i,j} T_{ij}\).
The function we want to estimate is whether or not the project takes longer than 70 days: \(\mathbb{1}(D \geq 70)\) just like before (using the indicator function). From Equation 4, we get:
Looking at the individual parts, you should be able to match it up to \(f, p, q\) with the main difference being that we are more explicit that there is a vector of independent random variables.
Now the bigger question is: what values are we going to use for the various \(\lambda_j\)? So if we take a step back, we want to make the long-tail event of \(D \geq 70\) happen more often. The obvious way is to shift out the mean of the exponentials of our importance distribution so that they happen more often. We'll try two general ideas:
Multiply all durations by 4.
Multiply only the durations on the critical path by some constant. The critical path in this case is task 1, 2, 4, 10.
Figure 3 shows the results of these experiments (the code is in the same: notebook). Notice we're only going up to 1M in this graph vs. 5M in the previous one.
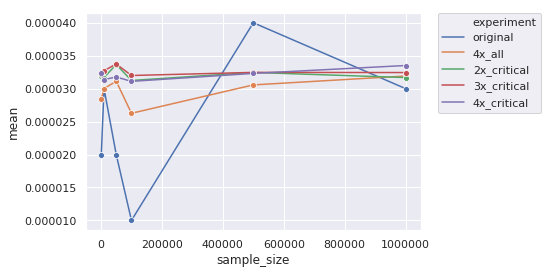
Figure 3: Estimated mean using various importance sampling distributions.
We can see that our first strategy (orange) of multiplying all durations isn't very good. Since we scale every distribution, we distorted the joint distribution too much causing issues (which eventually even out with large enough sample size). While it's convergence looks a bit smoother than the original case, it still takes around 500k+ samples to converge.
Looking at our critical path approach, it's much more efficient. We can see it's pretty stable even at small values like 10,000. As to which one is better, it's not obvious and it's a bit more of a subtle question. In any case, importance sampling can be extremely efficient with the big caveat that you need to pick the right importance distribution for your problem.
Estimating Marginal Likelihood in Variational Autoencoders
So how does all this help us with autoencoders? We all know that an autoencoder has two parts: a encoder and a decoder (also known as a generator). The latter can be used to sample from a distribution, for example, of images. Starting to sound familiar? Below is the (ugly) diagram I made of a VAE from my post on variational autoencoders.
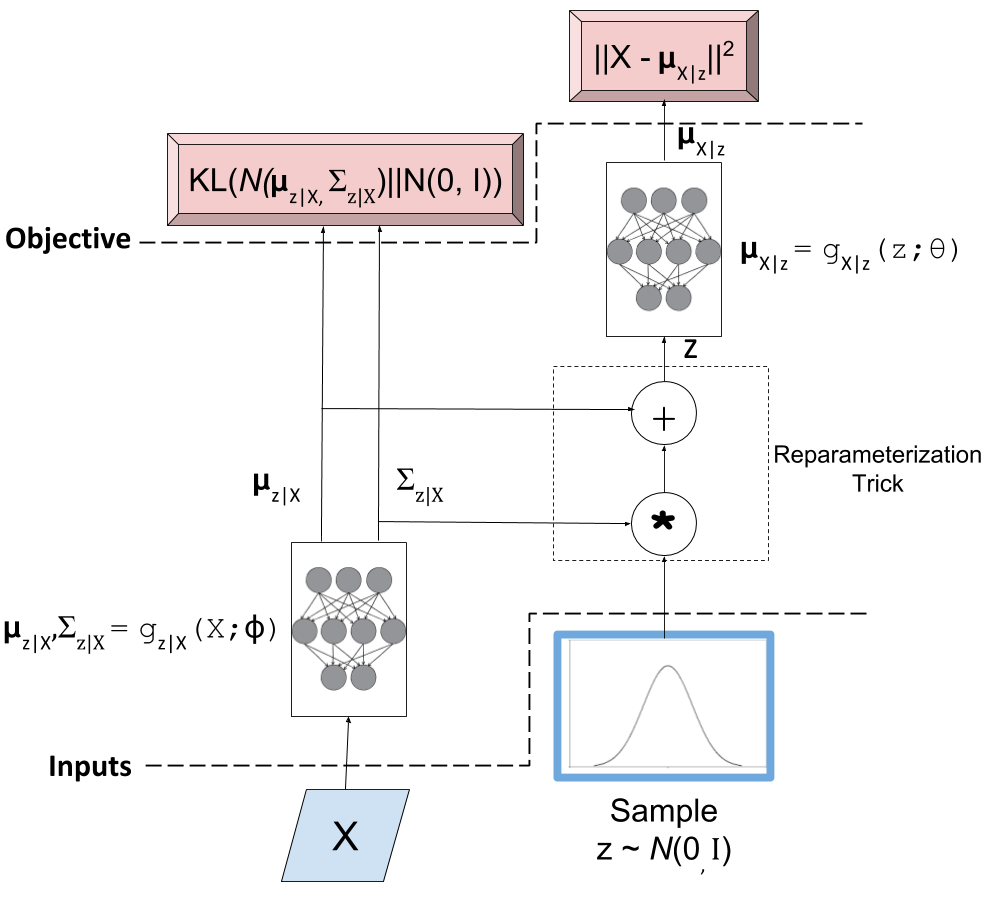
Figure 4: Variational Autoencoder Diagram
You can see the bottom left neural network is the encoder and the top right is the generator (or decoder). After training, we can sample a standard Gaussian, feed it into the generator, and out should pop a sample from your original data distribution. The big question is: does it?
Evaluating the quality of deep generative models is a hard thing to do usually because you don't know the actual data distribution. Instead, you just have a bunch of samples from it. One way to evaluate models is to look at the marginal likelihood of your model. That is, if your model is probabilistic conditional on some known random variable, we can estimate the probability of a data point \(X\) occurring given the model by:
Sampling many \(Z\) from the known latent distribution, and
Computing the average value of \(p_M(X|Z)\) for all the sampled \(Z\).
where \(X\) is our resultant sample from our data distribution (i.e. training data sample), \(Z\) is something we know how to sample from e.g. a Gaussian, and \(M\) is just indicating it's with respect to our model. More precisely, you can estimate the marginal likelihood via Monte Carlo sampling for a single data point \(X\) like so:
This is just like Equation 1 and it tells us the probability of seeing the data given our model \(M\). The marginal likelihood is a common tactic that we can use to compare models in Bayesian model comparison. Theoretically, this is a nice concept, we'll get a single number to tell us if one model is "better" than the other (given a particular dataset). Unfortunately, this is not really the case for many deep generative models especially ones dealing with images, see [2] for more details. The long and short of it is that any one metric doesn't necessarily correlate to improved qualitative performance; you need to evaluate it on a per task basis. However, we won't concern ourselves with that issue and proceed on to how we can estimate this metric for variational autoencoders.
So there are two main problems when trying to do this for a VAE. You need to:
Make the model fully probabilistic.
Efficiently sample from it.
We'll talk about both in the next two subsections.
Fully Probabilistic Variational Autoencoders
If you read my previous posts, you are probably wondering: aren't VAEs already probabilistic? I mean that's one the reasons why I like them so much! Well, it actually depends on how you define it. The main issue is that the output of the autoencoder.
So all the examples I've done up to now have been with images. In most images, each pixel is either a grey-scale integer from 0 to 255, or an RGB triplet composed of three integers from 0 to 255. In either case, we usually constrain the output layer of the generator network to use a sigmoid with continuous range [0,1]. This naturally maps to 0 to 255 with scaling but it's not exactly correct because we actually have integers, not a continuous value. Moreover, the loss function we apply usually doesn't match the image data.
For example, for grey-scale images, we usually apply a sigmoid output with a binary cross entropy loss (for each pixel). This is not the right assumption because a binary cross entropy loss maps to a Bernoulli (0/1) variable, definitely not the same thing as an integer in the [0,255] range. (This does work if you assume binarized pixels like in the Binarized MNIST dataset that I used for the Autoregressive Autoencoders post.) Another common example is to use the same sigmoid on the output layer but use a MSE loss function. This implicitly assumes a Gaussian on the output, which again, is not a valid assumption because it's continuous density is spread over the entire real-line.
So how can we deal with this problem? One method is to model each pixel intensity separately. That's exactly what the PixelRNN/PixelCNN paper [4] does. On the output, for each sub-pixel, it has a 256-way softmax to model each of the 0 to 255 integer values. Correspondingly, it puts a cross-entropy loss on each of the sub-pixels. This matches all the high-level assumptions of the data. There are only two problems.
First, it's a gigantic model! Having a 32x32x3 256-way softmax isn't even close to fitting on my 8GB GPU (I can do about a quarter of this size). It's also incredibly slow to train. This model is kind of a luxury for Google researchers who have unlimited hardware.
Second, the softmax is missing some assumptions about the continuity of the data. If the network is outputting pixel intensity of 127 but the actual is 128, those two should be pretty "close" together and result in a small error. However, with this method 127 is treated no differently than 255. Of course, after training with enough data the model's flexibility will be able to learn that they should be close but there is no built-in assumption. I personally couldn't really get this to work on CIFAR10.
Another more efficient method is described in [5]. It assumes that the underlying process works in two steps: (a) predict a continuous latent colour intensity (say between 0 to 255), and then (b) round the intensity to the nearest integer to get the observed pixel. By first using the latent continuous intensity, it's much more efficient to model and estimate (many two parameter distributions fit this bill vs. a 256 way softmax).
Assume the process first outputs a continuous distribution \(\nu\) representing the colour intensity. We'll model \(\nu\) as a mixture of logistic distributions parameterized by the mixture weights \(\pi\), and parameters of the logistics \(\mu_i, s_i\):
We then convert this intensity to a mass function by assigning regions of it to the 0 to 255 pixels:
where \(\sigma\) is the sigmoid function (recall sigmoid is the CDF of the logistic distribution) and x is an integer value between 0 and 255. This is additionally modified for the edge cases to integrate over the rest of the number line. So for \(0\) pixel intensity, we would integrate from \(-\infty\) to \(0.5\), and for the \(255\) intensity, we would integrate from \(254.5\) to \(\infty\).
The authors of [5] mention that this method naturally puts more mass on pixels 0 and 255, which are more commonly seen in images. Additionally using 5 mixtures results in pretty good performance, making it much more efficient to generate (5 mixtures means 2 * 5 + 5 = 15 parameters on each sub-pixel vs. 256-way softmax). Due to the significantly fewer parameters, it should also train faster.
The implementation of this is non-trivial. Thankfully the authors released their code. There are definitely some strange subtleties in implementing it due to numerical instability. I also have an implementation of it too. I tried to do it from scratch but in the end had to look at their code and try to reverse engineer it. I think I have something working, although the images I generate still have lots of artifacts, but I'm not sure if it's due to the loss or my weird CNN. You can check it out below.
Efficiently Estimating Marginal Likelihood using Importance Sampling
Finally, we are getting to the whole point of this article! So how can we estimate the marginal likelihood? Well the simplest way is to just apply Equation 7:
- For each point \(x\) in your test set:
Sample \(N\) \(\bf z\) vectors as standard independent Gaussians.
Use Equation 9 to estimate \(p_M(x|z)\) for each of the \(N\) samples. (depending on your generator, the pixels will be independent or conditional on each other).
Use Equation 7 to estimate the marginal likelihood \(P_M(X)\) by averaging over all the probabilities.
But... there's a bit problem with this method: the curse of dimensionality! Recall, our standard VAE has a vector of latent \(Z\) variable distributed as independent standard Gaussians. To get good coverage of the latent space, we would have to sample an exponential number of samples from the generator. Obviously not something we want to do for a 100 dimension latent space. If only we could sample from an alternate distribution that would allow us compute the same quantity more efficiently... Enter importance sampling.
Recall from our discussion above for importance sampling, we need to select an importance distribution that has a similar shape to our original distribution. Our nominal distributions are independent standard Gaussians so we need something similar in shape... how about the scaled and shifted Gaussians from our encoder?! In fact, this is the perfect importance distribution because it's precisely the same shape and is designed to ensure that there is density under the function we care about: \(p(x|z)\). (This is actually the exact motivation we had for having the "encoder" in a VAE, we want to make the probability of \(p(x|z)\) high without having to randomly sample about the \(Z\) space.) Of course, we can't just use it directly because that would bias the estimate, so that's where importance sampling comes in.
So all of that just to say that we use the encoder's outputs to sample \(Z\) values from the scaled and shifted Gaussians in order to ultimately compute an estimate for \(P(X)\). The final equation to estimate the likelihood for a single data point \(X\) looks something like this:
where \(\mu, \sigma\) are the corresponding outputs from the encoder network. Compared to Equation 7, \(N\) can be significantly smaller (I used \(N=128\) in the experiments).
Experiments
I implemented this for two vanilla VAEs corresponding to binarized MNIST and CIFAR10. You can find the code on my Github. Table 1 shows the results of these two experiments using the two standard metrics: log marginal likelihood and the bits per pixel. The latter metric simply is the negative logarithm base 2 likelihood divided by the total number of (sub-)pixels. This is supposed to give the theoretical average number of bits you need to encode the information using this encoding scheme (information theory result).
Model |
log p(x) |
Bits/pixel (\(-log_2 p(x) / pixels\)) |
|---|---|---|
Binarized MNIST |
-87.08 |
0.16 |
CIFAR10 |
-20437 |
6.65 |
My results are relatively poor compared to the state of the art. For example, in the IAF paper [3], they report \(\log p(x)\) of \(-81.08\) vs. my VAE of \(-87.08\). While for CIFAR10, they achieve results around the 3.11 bits/pixel range vs. my implementation of 6.65. My only consolation is that one of the previous results reports a 8.0 bits/pixel, so at least it's better than that one! These state of the art models is something that I'm interested in and I'm probably going to get around to looking at them sooner or later.
Implementation Details
The implementation of this was a bit more complicated than I had expected for two reasons: making the autoencoder fully probabilistic (see section above) and then some of the details when actually computing the importance samples.
For the binarized MNIST, it was pretty straight forward to implement. Here are the notes.
The output just needs to be a sigmoid, which is interpreted as the \(p\) parameter of a Bernoulli variable since we're modelling binarized output data (not grey-scale).
\(\log p(x|z)\) is simply a binary cross entropy expression.
\(p(z)\) and \(q(z)\) are just Gaussian densities.
I calculated all the individual terms in log-space (\(\log p(x|z), \log p(x), \log q(x)\)), which gets you the logarithm of the expression on the inside of the summation in Equation 10. However, you still need to convert back to non-log-space and do the summation, and then take the logarithm to get \(\log p(x)\). To do this efficiently, you need to use the logsumexp function, otherwise you'll get some numerical instability when you try to take exponentials. Fortunately, this is a common operation and numpy has a function for it.
For CIFAR 10, it was a bit more complicated and I had to make a few more tweaks (above and beyond the above notes) in order to get things working:
To make the VAE fully probabilistic, I used the mixtures of logistics technique described above except with only one logistic distribution.
To make things converge consistently, I also had to constrain the standard deviation parameter of the latent variable \(z\), as well as the equivalent inverse parameter s of the logistic distribution. The former used a tanh multiplied by 5, the latter used a sigmoid scaled by 7. These are pretty wide ranges for the distributions, which seem to work okay. Letting it by any real number, at least in my experience, causes lots of NaNs to appear.
The loss function was incredibly difficult to get right. In the end, I followed almost exactly what Kingma [5] did in his implementation which is here: https://github.com/openai/pixel-cnn. It was incredibly hard to decode what he was doing though. I had to spend a lot of time going step-by-step understanding what he did with all the random operations and constants going on. A big trick was that you had to do some funky stuff to check for invalid values or else Tensorflow would propagate NaNs through. I put some comments in my implementations and my naming is maybe a bit better? So hopefully both you and I can remember next time we read it.
I used ResNet architecture as a base for both the encoder and decoder. I initially turned off batch normalization but the network had a lot of trouble fitting. Batch norm is really useful!
My actual reconstructed final images are pretty terrible. There is a lot of corruption but at very regular grid-like patterns. I was wondering if it was due to the CNN strides that I was using. In retrospect though, I think it might be because I'm using a single logistic distribution. In the paper, they used a mixture of five, which probably will have much better behaviour.
My code isn't the cleanest because I'm really just prototyping here. Although somehow each time I try to write a VAE, I clean it up a bit more. It's getting there but still nothing I would actually put into production.
Conclusion
Well all that to explain a "simple" concept: how to estimate the marginal likelihood with variational autoencoders. I do kind of like these types of problems where a seemingly simple task requires you to: (a) understand basic statistics/probability (importance sampling), (b) deeply understand the underlying method (VAEs, fully probabilistic models with mixtures of logistics) (c) get the implementation details right! These posts always seem to take longer than I initially think. Every topic is much deeper than I thought and I can't help but going down the rabbit hole to understand the details (to a satisficing degree). Anyways, look out for more posts in the future, I really do want to finally get to state-of-the-art (non-GAN) generative models but I keep getting distracted by all these other interesting topics!
Further Reading
[1] "Importance Sampling", Art Owen, https://statweb.stanford.edu/~owen/mc/Ch-var-is.pdf
[2] "A Note on The Evaluation of Generative Models", Lucas Theis, Aäron van den Oord, Matthias Bethge, ICLR 2016.
[3] "Improving Variational Inference with Inverse Autoregressive Flow", Diederik P. Kingma, Tim Salimans, Rafal Jozefowicz, Xi Chen, Ilya Sutskever, Max Welling, NIPS 2016
[4] "Pixel Recurrent Neural Networks", Aaron van den Oord, Nal Kalchbrenner, Koray Kavukcuoglu, https://arxiv.org/pdf/1601.06759.pdf
[5] "PixelCNN++: Improving the PixelCNN with Discretized Logistic Mixture Likelihood and Other Modifications", Tim Salimans, Andrej Karpathy, Xi Chen, Diederik P. Kingma, http://arxiv.org/abs/1701.05517.
PixelCNN++ code on Github: https://github.com/openai/pixel-cnn
Wikipedia: Importance Sampling, Monte Carlo methods
Previous posts: Variational Autoencoders, A Variational Autoencoder on the SVHN dataset, Semi-supervised Learning with Variational Autoencoders, Autoregressive Autoencoders, Variational Autoencoders with Inverse Autoregressive Flows