An Introduction to Stochastic Calculus
Through a couple of different avenues I wandered, yet again, down a rabbit hole leading to the topic of this post. The first avenue was through my main focus on a particular machine learning topic that utilized some concepts from physics, which naturally led me to stochastic calculus. The second avenue was through some projects at work in the quantitative finance space, which is one of the main applications of stochastic calculus. Naively, I thought I could write a brief post on it that would satisfy my curiosity -- that didn't work out at all! The result is this extra long post.
This post is about stochastic calculus, an extension of regular calculus to stochastic processes. It's not immediately obvious but the rigour needed to properly understand some of the key ideas requires going back to the measure theoretic definition of probability theory, so that's where I start in the background. From there I quickly move on to stochastic processes, the Wiener process, a particular flavour of stochastic calculus called Itô calculus, and finally end with a couple of applications. As usual, I try to include a mix of intuition, rigour where it helps intuition, and some simple examples. It's a deep and wide topic so I hope you enjoy my digest of it.
1 Motivation
Many physical phenomena (and financial ones) can be modelled as a stochastic process that is described using a stochastic differential equation. Both of these things were probably not included in most introductory courses on either probability or calculus. Starting with stochastic processes, the easiest way to think about it is a collection of random variables indexed by time. So instead of a single deterministic value at each time \(t\), we have a random variable instead (usually with some relationship or common property with the other ones). So while on the surface it seems relatively simple, one of the big complexities we run into is when we let \(t\) be continuous, which we will see in detail later.
Stochastic differential equations defined on continuous time are a very natural way to model many different phenomena. A common stochastic differential equation called the Langevin equation is used to model many types of stochastic phenomena:
where \(X(t)\) is a stochastic process, \(\alpha, \beta\) can be a function of both \(X\) and time \(t\), and a noise term \(\eta(t)\). The noise term is what makes this differential equation special by introducing a special type of randomness. And while this is just a single example, it does have many characteristics that show up in other applications of stochastic calculus.
Intuitively, the noise term \(\eta(t)\) represents "random fluctuations" such as a particle's random collisions with other molecules in a fluid, or the random fluctuations of a stock price. To be precise about these "random fluctuations", we first must specify some of their characteristics such as their time correlation function:
which should be a decreasing function of \(\tau\) since they are random fluctuations and shouldn't have lasting effects. But this can get messy relatively quickly so we usually look for more clean abstractions to describe these systems.
The assumption that is commonly used is that the random fluctuations are not correlated at all. This can be justified if the time scale of interest is much bigger than the random fluctuations. From this assumption, we have:
where \(c\) is a constant and \(\delta(\tau)\) is the Dirac delta function. This implies that the random fluctuations are entirely uncorrelated even for infinitesimal timescales. The other corresponding assumption is that at each timestep \(t\) the random variable \(\eta(t)\) is a zero mean Gaussian.
In some ways, \(\eta(t)\) simplifies things; in others, it makes them much more complex. The first thing to note is that \(\eta(t)\) is a theoretical construct -- there is no random process that can have its properties. We can see that from Equation 1.3 where we use the theoretical Dirac delta function. This also implies that the variance of \(\eta(t)\) is infinite (\(C(\tau=0)\)). This construction also has a flat power spectral density of all frequencies, implying an infinite bandwidth signal (see Wikipedia), which again is not physically realizable.
Another consequence of this definition is that \(\eta(t)\) is discontinuous everywhere. The value at \(\eta(t)\) can be totally different at a small time increment later (\(\eta(t + dt)\)). This makes simple operations like integration much more difficult. Going back to our stochastic differential equation from Equation 1.1, we can multiply through by \(dt\) and integrate both sides to try to get:
The first integral on the right hand side is a standard one that generally we know how to solve using the tools of calculus. The second integral involving \(\eta(t)\) is where we run into an issue. It is precisely this problem that has spawned a new branch of mathematics called stochastic calculus, which is the topic of this post.
2 Stochastic Processes
2.1 Probability Spaces & Random Variables
(Note: Skip this part if you're already familiar with the measure theoretic definition of probability.)
We're going to dive into the measure theoretic definition of probability, attempting to give some intuition while still maintaining some level of rigour. First, let's examine the definition of a probability space \((\Omega, {\mathcal {F}}, P)\). This is the same basic idea you learn in a first probability course except with fancier math.
\(\Omega\) is the sample space, which defines the set of all possible outcomes of an experiment. In finite sample spaces, any subset of the sample space is called an event. Another way to think about events is any grouping of objects you would want to measure the probability on (e.g., individual elements of \(\Omega\), unions of elements, or even the empty set).
However, this type of reasoning breaks down when we have certain types of infinite sample spaces (e.g., real line). For this, we need to define an event more precisely with an event space \(\mathcal{F} \subseteq 2^{\Omega}\) (\(2^{\Omega}\) denotes the power set) using a construction called a \(\sigma\)-algebra ("sigma algebra"):
Let \(\Omega\) be a non-empty set, and let \(\mathcal{F}\) be a collection of subsets of \(\Omega\). We say that \(\mathcal{F}\) is a \(\sigma\)-algebra: if:
The empty set belongs to \(\mathcal{F}\).
Whenever a set \(A\) belongs to \(\mathcal{F}\), its compliment \(A^c\) also belongs to \(\mathcal{F}\) (closed under complement).
Whenever a sequence of sets \(A_1, A_2, \ldots\) belongs to \(\mathcal{F}\), their union \(\cup_{n=1}^{\infty} A_n\) also belongs to \(\mathcal{F}\) (closed under countable unions -- implies closed under countable intersection).
The elements of a \(\sigma\)-algebra are called measurable sets, and the pair \((\Omega, \mathcal{F})\) define a measurable space.
Thus, we wish our event space \(\mathcal{F}\) to be a \(\sigma\)-algebra and when combined with \(\Omega\), define a measurable space. This sounds complicated but it basically guarantees that the subsets of \(\Omega\) that we use for events have all the nice properties we would expect from probabilities.
Intuitively, measurable spaces help makes the notion of "size" or "volume" precise by defining the "chunks" of "volume". Using a physical analogy, you want to make sure that no matter how you combine non-overlapping "chunks" (i.e., unions of disjoint sets), you end up with a consistent measure of "volume". Again, this is only really needed with infinite (non-countable) sets. For finite event spaces, we can usually just use the power set \(2^{\Omega}\) as the event space, which has all these properties above.
And this brings us to the last part of probability spaces:
A probability measure \(P\) on an event space \(\mathcal{F}\) is a function that:
Maps events to the unit interval \([0, 1]\),
Returns \(0\) for the empty set and \(1\) for the entire space,
Satisfies countable additivity for all countable collections of events \(\{E_i\}\) of pairwise disjoint sets:
\begin{equation*} P(\cup_{i\in I} E_i) = \Sigma_{i\in I} P(E_i) \tag{2.1} \end{equation*}
These properties should look familiar as they are the three basic ones axioms everyone learns when first studying probability. The only difference is that we're formalizing them, particularly the last one where we may not have seen it with respect to infinite collections of events.
Going back to the "volume" analogy above, the probability measure maps the "chunks" of our "volume" to \([0,1]\) (or non-negative real numbers for general measures) but in a consistent way. Due to the way we've defined event spaces as \(\sigma\)-algebra's along with the third condition from Equation 2.1, we get a consistent measurement of "volume" regardless of how we combine the "chunks". Again, for finite sample spaces, it's not too hard to imagine this function but for continuous sample spaces, it gets more complicated. All this is essentially to define a rigorous construction that matches our intuition of basic probability with samples spaces, events, and probabilities.
Finally, for a given probability space \((\Omega, {\mathcal {F}}, P)\):
A random variable \(X\) 1 is a measurable function \(X:\Omega \rightarrow E \subseteq \mathbb{R}\) where:
\(X\) must part of a measurable space, \((E, \mathcal{S})\) (recall: \(\mathcal{S}\) defines a \(\sigma\)-algebra on the set \(E\)). For finite or countably infinite values of \(X\), we generally use the powerset of \(E\). Otherwise, we will typically use the Borel set for uncountably infinite sets (e.g., the real numbers).
For all \(s \in \mathcal{S}\), the pre-image of \(s\) under \(X\) is in \(\mathcal{F}\). More precisely:
\begin{equation*} \{X \in \mathcal{s}\} \in \mathcal{F} := \{\omega \in \Omega | X(\omega) \in s\} \in \mathcal{F} \tag{2.2} \end{equation*}
We use random variables to map outcomes from our event space to the real line (e.g., a RV for a coin flip where heads maps to 1 and tails maps to 0). However, the mapping must also have the same consistency as we defined above. So this definition basically ensures that every value that \(X\) can take on (which must be measurable) has a mapping to one of the measurable events in our original event space \(\mathcal{F}\). We use the notation \(\sigma(X)\) to denote the collection of all subsets of Equation 2.2, which form the \(\sigma\)-algebra implied by the random variable \(X\).
If we didn't have this condition then either: (a) we couldn't properly measure \(X\)'s "volume" because our "chunks" would be inconsistent (constraint 1), or (b) we wouldn't be able to map it back to "chunks" in our original probability space and apply \(P\) to evaluate the random variable's probability. If this all seems a little abstract, it is, but that's what we need when we're dealing with uncountable infinities. Again, for the finite cases, all of these properties are trivially met.
Using the probability measure \(P\), one can calculate the probability of \(X \in \mathcal{S}\) using Equation 2.2:
where \(s \subseteq \mathcal{S}\) and \(f\) is the corresponding event in \(\mathcal{F}\). We can take \(s = \{x\}\) to evaluate the random variable at a particular value. Equation 2.3 basically says that we map backwards from a set of real numbers (\(s\)) to a set of values in the sample space (i.e., an event given by Equation 2.2) using the inverse of function \(X\). From the event in our event space \(f \subseteq \mathcal{F}\), which is guaranteed to exist because of property (2), we know how to compute the probability using \(P\).
So a random variable then allows us to map to real numbers from our original sample space (\(\Omega\)). Often times our sample space has no concept of numbers (e.g., heads or tails) but random variables allow us to assign real numbers to those events to calculate things like expected values and variances.
For many applications of probability, understanding the above is overkill. Most practitioners of probability can get away with the "first stage" (see box below) of learning probability. However specifically for stochastic calculus, the above helps us learn it beyond a superficial level (arguably) because we quickly get into situations where we need to understand the mathematical rigour needed for uncountable infinities.
Example 1: Sample Spaces, Events, Probability Measures, and Random Variables
(From Wikipedia)
Assume we have a standard 52 card playing deck without any jokers, and our experiment is that we draw a card randomly from this set. The sample space \(\Omega\) is a set consisting of the 52 cards. An event \(A \subseteq \mathcal{F}\) is any subset of \(\Omega\), i.e., the powerset \(\mathcal{F} = 2^{\Omega}\). So that would include the empty set, any single element, or even the entire sample space. Some examples of events:
"Cards that are red and black at the same time" (0 elements)
"The 5 of Hearts" (1 element)
"A King" (4 elements)
"A Face card" (12 elements)
"A card" (52 elements)
In the case where each card is equally likely to be drawn, we can define a probability measure for event \(A\) as:
We can additionally define a random variable as:
Which is a mapping from our sample space \(\Omega\) to a (finite) subset of the real numbers \(\{0, 1\}\). We can calculate probabilities using Equation 2.3, for example \(X = 1\):
The implied \(\sigma\)-algebra of this random variable can be defined as: \(\sigma(X) = \{ \emptyset, \text{"all red cards"}, \text{"all black cards"}, \Omega \} \subset \mathcal{F}\).
The Two Stages of Learning Probability Theory
(Inspired by the notes from Chapter 1 in [1])
Probability theory is generally learned in two stages. The first stage describes discrete random variables that have a probability mass function, and continuous random variables that have a density. We learn to compute basic quantities from these variables such as expectations, variances, and conditionals. We learn about standard distributions and their properties and how to manipulate them such as transforming continuous random variables. This gets us through most of the standard applications of probability from basic statistical tests to likelihood functions.
The second stage of probability theory dives deep into the rigorous measure theoretic definition. In this definition, one views a random variable as a function from a sample space \(\Omega\) to a subset of the real numbers \(\mathbb{R}\). Certain subsets of \(\Omega\) are called events, and the collection of all possible events form a \(\sigma\)-algebra \(\mathcal {F}\). Each set \(A\) in \(\mathcal {F}\) has probability \(P(A)\), defined by the probability measure \(P\). This definition handles both discrete and continuous variables in a elegant way. It also (as you would expect) introduces a lot of details underlying the results that we learn in the first stage. For example, a random variable is not the same thing as a distribution (random variables can have multiple probability distributions depending on the associated probability measure). Another quirk that we often don't think about is that not all distributions have a density function (although most of the distributions we study will have a density). Like many things in applied mathematics, understanding of the rigorous definition is often not needed because most of the uses do not hit the corner cases where it matters (until it doesn't). It's also a whole lot of work to dig into so most folks like me are happy to understand it only "to a satisfactory degree".
2.2 Stochastic Processes
Here's the formal definition of a stochastic process from [2]:
Suppose that \((\Omega,\mathcal{F},P)\) is a probability space, and that \(T \subset \mathbb{R}\) is of infinite cardinality. Suppose further that for each \(t \in T\), there is a random variable \(X_t: \Omega \rightarrow \mathbb{R}\) defined on \((\Omega,\mathcal{F},P)\). The function \(X: T \times \Omega \rightarrow \mathbb{R}\) defined by \(X(t, \omega) = X_t(\omega)\) is called a stochastic process with indexing set \(T\), and is written \(X = \{X_t, t \in T\}\).
That's a mouthful! Let's break this down and interpret the definition more intuitively. We've already seen probability spaces and random variables in the previous subsection. The first layer of a stochastic process is that we have a bunch of random variables that are indexed by some set \(T\). Usually \(T\) is some total ordered sequence such as a subset of the real line (e.g., \((0, \infty)\)) or natural numbers (e.g., \(0, 1, 2, 3 \ldots\)), which intuitively correspond to continuous and discrete time.
Next, we turn to the probability space on which each random variable is defined on \((\Omega,\mathcal{F},P)\). The key thing to note is that the elements of the sample space \(\omega \in \Omega\) are infinite sets that correspond to experiments performed at each index in \(T\). (Note: by definition it's infinite because otherwise it would just be a random vector.) For example, flipping a coin at every (discrete) time from \(0\) to \(\infty\), would define a specific infinite sequence of heads and tails \(\omega = \{H, T, H, H, H, T, \ldots\}\). So each random variable \(X_t\) can depend on the entire sequence of the outcome of this infinite "experiment". That is, \(X_t\) is a mapping from outcomes of our infinite experiment to (a subset of) the real numbers: \(X_t: \Omega \rightarrow E \subseteq \mathbb{R}\). It's important to note that in this general definition we have no explicit concept of time, so we can depend on the "future". To include our usual concept of time, we need an additional concept (see adapted processes below).
Finally, instead of viewing the stochastic process as a collection of random variables indexed by time, we could look at it as a function of both time and the sample space i.e., \(X(t, \omega) = X_t(\omega)\). For a given outcome of an experiment \(\omega_0\), the deterministic function generated as \(X(t, \omega=\omega_0)\) is called the sample function. However, mostly we like to think of it as having a random variable at each time step indicated by this notation: \(X = \{X_t, t \in T\}\). We sometimes use the notation \(X(t)\) to refer to the random variable at time \(t\) or the stochastic process itself.
Stochastic processes can be classified by the nature of the values the random variables take and/or the nature of the index set:
Discrete and Continuous Value Processes: \(X(t)\) is discrete if at all "times" \(X(t)\) takes on values in a countable set (i.e., can be mapped to a subset of the natural numbers); otherwise \(X(t)\) is continuous.
Discrete and Continuous Time Processes: \(X(t)\) is discrete time process if the index set is countable (i.e., can be mapped to a subset of the natural numbers), otherwise it is a continuous time process.
Generally continuous time processes are harder to analyze and will be the focus of later sections. The next two discrete time examples give some intuition about how to match the formal definition to concrete stochastic processes.
Example 2: Bernoulli Processes
One of the simplest stochastic processes is a Bernoulli Process, which is a discrete value, discrete time process. The main idea is that a Bernoulli process is a sequence of independent and identically distributed Bernoulli trials (think coin flips) at each time step.
More formally, our sample space \(\Omega = \{ (a_n)_1^{\infty} : a_n \in \{H, T\} \}\) is the set of all infinite sequences of "heads" and "tails". It turns out the event space and the probability measure are surprisingly complex to define so I've put those details in Appendix A.
We can define the random variable given an outcome of infinite tosses \(\omega\):
for \(\omega = \omega_1 \omega_2 \omega_3 \ldots\), where each \(\omega_i\) is the outcome of the \(i^{th}\) toss. For all values of \(t\), the probability \(P(X_t = 1) = p\), for some constant \(p \in [0, 1]\).
Example 3: One Dimensional Symmetric Random Walk
A simple one dimensional symmetric random walk is a discrete value, discrete time stochastic process. An easy way to think of it is: starting at 0, at each time step, flip a fair coin and move up (+1) if heads, otherwise move down (-1).
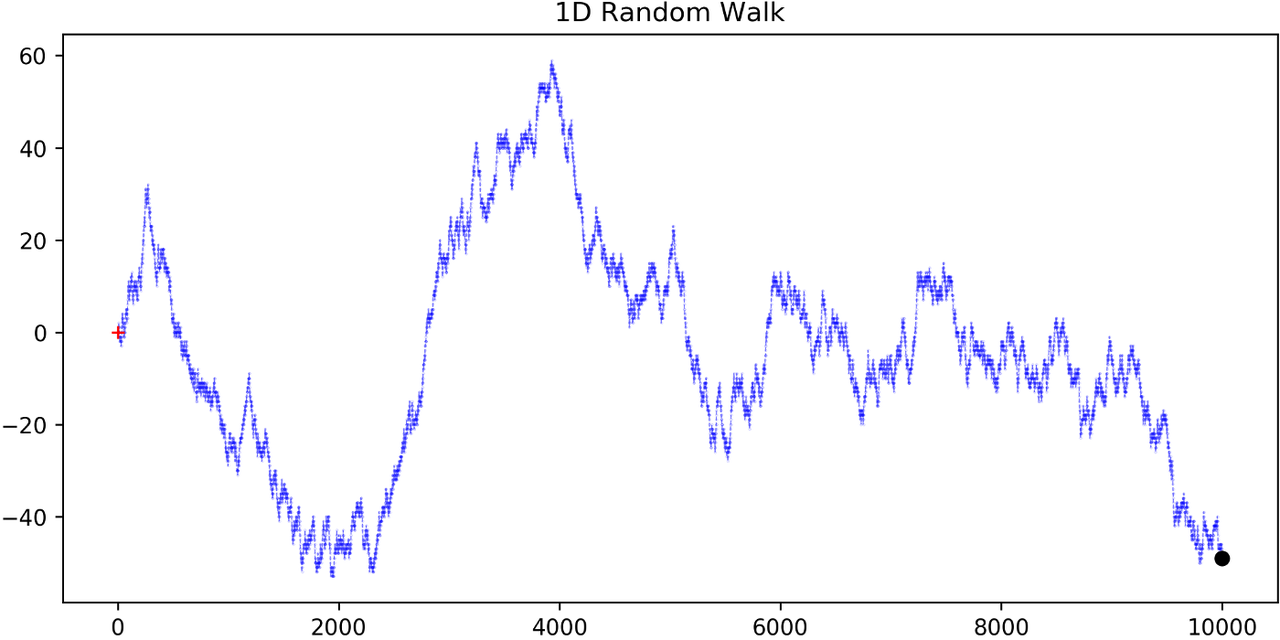
Figure 1: 1D Symmetric Random Walk (source)
This can be defined in terms of the Bernoulli process \(X_t\) from Example 2 with \(p=0.5\) (with the same probability space):
Notice that the random variable at each time step depends on all the "coin flips" \(X_t\) that came before it, which is in contrast to just the current "coin flip" for the Bernoulli process.
Another couple of results that we'll use later. The first is that the increments between any two given non-overlapping pairs of integers \(0 = k_0 < k_1 < k_2 < \ldots < k_m\) are independent. That is, \((S_{k_1} - S_{k_0}), (S_{k_2} - S_{k_1}), (S_{k_3} - S_{k_2}), \ldots, (S_{k_m} - S_{k_{m-1}})\) are independent. We can see this because for any combination of pairs of these differences, we see that the independent \(X_t\) variables don't overlap, so the sum of them must also be independent.
Moreover, the expected value and variance of the differences is given by:
Which means that the variance of the symmetric random walk accumulates at a rate of one per unit time. So if you take \(l\) steps from the current position, you can expect a variance of \(l\). We'll see this pattern when we discuss the extension to continuous time.
2.3 Adapted Processes
Notice that in the previous section, our definition of stochastic process included a random variable \(X_t: \Omega \rightarrow E \subseteq \mathbb{R}\) where each \(\omega \in \Omega\) is an infinite sequence representing a given outcome for the infinitely long experiment. This implicitly means that at "time" \(t\), we could depend on the "future" because we are allowed to depend on any tosses, including those greater than \(t\). In many applications, we do want to interpret \(t\) as time so we wish to restrict our definition of stochastic processes.
An adapted stochastic process is one that cannot "see into the future". Informally, it means that for any \(X_t\), you can determine it's value by only seeing the outcome of the experiment up to time \(t\) (i.e., \(\omega_1\omega_2\ldots\omega_t\) only).
To define this more formally, we need to introduce a few technical definitions. We've already seen the definition of the \(\sigma\)-algebra \(\sigma(X)\) implied by the random variable \(X\) in a previous subsections. Suppose we have a subset of our event space \(\mathcal{G}\), we say that \(X\) is \(\mathcal{G}\)-measurable if every set in \(\sigma(X) \subseteq \mathcal{G}\). That is, we can use \(\mathcal{G}\) to "measure" anything we do with \(X\).
Using this idea, we define the concept of a filtration on our event space \(\mathcal{F}\) and our index set \(T\):
A filtration \(\mathbb{F}\) is a ordered collection of subsets \(\mathbb{F} := (\mathcal{F_t})_{t\in T}\) where \(\mathcal{F_t}\) is a sub-\(\sigma\)-algebra of \(\mathcal{F}\) and \(\mathcal{F_{t_1}} \subseteq \mathcal{F_{t_2}}\) for all \(t_1 \leq t_2\).
To break this down, we're basically saying that our event space \(\mathcal{F}\) can be broken down into logical "sub event spaces" \(\mathcal{F_t}\) such that each one is a superset of the next one. This is precisely what we want where as we progress through time, we gain more "information" but never lose any. We can also use this idea of defining a sub-\(\sigma\)-algebra to formally define conditional probabilities, although we won't cover that in this post (see [1] for a more detailed treatment).
Using the construct of a filtration, we can define:
A stochastic process \(X_t : T \times \Omega\) is adapted to the filtration \((\mathcal{F_t})_{t\in T}\) if the random variable \(X_t\) is \(F_t\)-measurable for all \(t\).
This basically says that \(X_t\) can only depend on "information" before or at time \(t\). The "information" available is encapsulated by the \(\mathcal{F_t}\) subsets of the event space. These subsets of events are the only ones we can compute probabilities on for that particular random variable, thus effectively restricting the "information" we can use. As with much of this topic, we require a lot of rigour in order to make sure we don't have weird corner cases. The next example gives more intuition on the interplay between filtrations and random variables.
Example 4: An Adapted Bernoulli Processes
First, we need to define the filtration that we wish to adapt to our Bernoulli Process. Borrowing from Appendix A, repeating the two equations:
This basically defines two events (i.e., sets of infinite coin toss sequences) that we use to define our probability measure. We define our first sub-\(\sigma\)-algebra using these two sets:
Let's notice that \(\mathcal{F}_1 \subset \mathcal{F}\) (by definition since this is how we defined it). Also let's take a look at the events generated by the random variable for heads and tails:
Thus, \(\sigma(X_1) = \mathcal{F}_1\) (the \(\sigma\)-algebra implied by the random variable \(X_1\)), meaning that \(X_1\) is indeed \(\mathcal{F}_1\)-measurable as required.
Let's take a closer look at what this means. For \(X_1\), Equation 2.11 defines the only types of events we can measure probability on, in plain English: empty set, every possible outcome, outcomes starting with the first coin flip as heads, and outcomes starting with the first coin flip as tails. This corresponds to probabilities of \(0, 1, p\) and \(1-p\) respectively, precisely the outcomes we would expect \(X_1\) to be able to calculate.
On closer examination though, this is not exactly the same as a naive understanding of the situation would imply. \(A_H\) contains every infinitely long sequence starting with heads -- not just the result of the first flip. Recall, each "time"-indexed random variable in a stochastic process is a function of an element of our sample space, which is an infinitely long sequence. So we cannot naively pull out just the result of the first toss. Instead, we group all sequences that match our criteria (heads on the first toss) together and use that as a grouping to perform our probability "measurement" on. Again, it may seem overly complicated but this rigour is needed to ensure we don't run into weird problems with infinities.
Continuing on for later "times", we can define \(\mathcal{F}_2, \mathcal{F}_3, \ldots\) and so on in a similar manner. We'll find that each \(X_t\) is indeed \(\mathcal{F}_t\) measurable (see Appendix A for more details), and also find that each one is a superset of its predecessor. As a result, we can say that the Bernoulli process \(X(t)\) is adapted to the filtration \((\mathcal{F_t})_{t\in \mathbb{N}}\) as defined in Appendix A.
2.4 Weiner Process
The Weiner process (also known as Brownian motion) is one of the most widely studied continuous time stochastic processes. It occurs frequently in many different domains such as applied math, quantitative finance, and physics. As alluded to previously, it has many "corner case" properties that do not allow simple manipulation, and it is one of the reasons why stochastic calculus was discovered. Interestingly, there are several equivalent definitions but we'll start with the one defined in [1] using scaled symmetric random walks.
2.4.1 Scaled Symmetric Random Walk
A scaled symmetric random walk process is an extension of the simple random walk we showed in Example 3 except that we "speed up time and scale down the step size" and extend it to continuous time. More precisely, for a fixed positive integer \(n\), we define the scaled random walk as:
where \(S_{nt}\) is a simple symmetric random walk process, provided that \(nt\) is an integer. If \(nt\) is not an integer, we'll simply define \(W^{(n)}(t)\) as the linear interpolation between it's nearest integer values.
A simple way to think about Equation 2.13 is that it's just a regular random walk with a scaling factor. For example, \(W^{(100)}(t)\) has it's first step (integer step) at \(t=\frac{1}{100}\) instead of \(t=1\). To adjust for this compression of time we scale the process by \(\frac{1}{\sqrt{n}}\) to make the math work out (more on this later). The linear interpolation is not that relevant except that we want to start working in continuous time. Figure 2 shows a visualization of this compressed random walk.
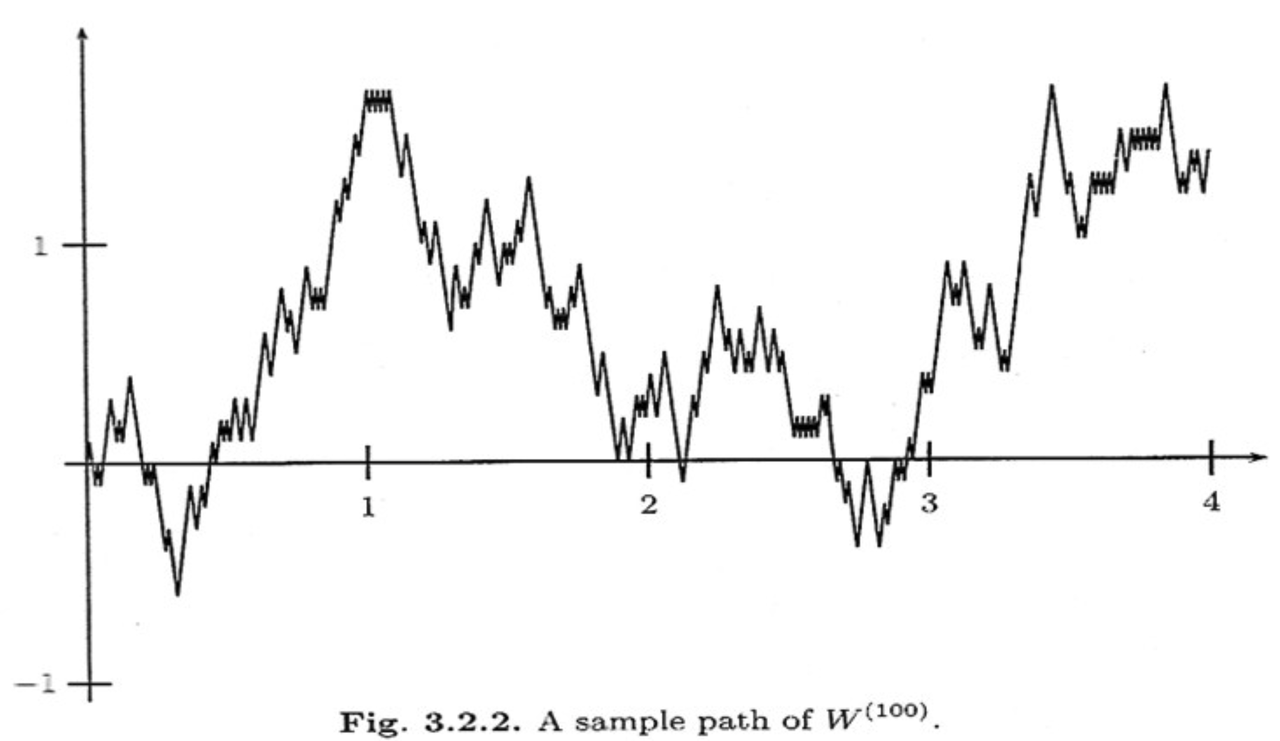
Figure 2: Scaled Symmetric Random Walk (source)
Since this is just a simple symmetric random walk (assuming we're analyzing it with its integer steps), the same properties hold as we discussed in Example 3. Namely, that non-overlapping increments are independent. Additionally, for \(0 \leq s \leq t\), we have:
where we use the square root scaling to end up with variance accumulating still at one unit per time.
Another important property is called the quadratic variation, which is calculated along a specific path (i.e., there's no randomness involved). For a scaled symmetric random walk where we know the exact path it took up to time \(t\), we get:
This results in the same quantity as the variance computation we have (for \(s=0\)) in Equation 2.14 but is conceptually different. The variance is an average over all paths while the quadratic variation is taking a realized path, squaring all the values, and then summing them up. In the specific case of a Wiener process, they result in the same thing (not always the case for general stochastic processes).
Finally, as you might expect, we wish to understand what happens to the scaled symmetric random walk when \(n \to \infty\). For a given \(t\geq 0\), let's recall a few things:
\(E[W^{(n)}(t)] = 0\) (from Equation 2.14 with \(s = 0\)).
\(Var[W^{(n)}(t)] = t\) (from Equation 2.14 with \(s = 0\)).
\(W^{(n)}(t) = \frac{1}{\sqrt{n}} \sum_{i=1}^t X_t\) for Bernoulli process \(X(t)\).
The central limit theorem states that \(\frac{1}{\sqrt{n}}\sum_{i=1}^n Y_i\) converges to \(\mathcal{N}(\mu_Y, \sigma_Y^2)\) as \(n \to \infty\) for IID random variables \(Y_i\) (given some mild conditions).
We can see that our symmetric scaled random walk fits precisely the conditions as the central limit theorem, which means that as \(n \to \infty\), \(W^{(n)}(t)\) converges to a normal distribution with mean \(0\) and variance \(t\). This limit is in fact the method in which we'll define the Wiener process in the next subsection.
2.4.2 Wiener Process Definition
We finally arrive at the definition of the Wiener process, which will be the limit of the scaled symmetric random walk as \(n \to \infty\). We'll define it in terms of the properties of this limiting distribution, many of which are inherited from the scaled symmetric random walk:
Given probability space \((\Omega, \mathcal{F}, P)\), suppose there is a continuous function of \(t \geq 0\) that also depends on \(\omega \in \Omega\) denoted as \(W(t) := W(t, \omega)\). \(W(t)\) is a Wiener process if the following are satisfied:
\(W(0) = 0\);
All increments \(W(t_1) - W(t_0), \ldots, W(t_m) - W(t_{m-1})\) for \(0 = t_0 < t_1 < \ldots < t_{m-1} < t_{m}\) are independent; and
Each increment is distributed normally with \(E[W(t_{i+1} - t_i)] = 0\) and \(Var[W(t_{i+1} - t_i)] = t_{i+1} - t_i\).
We can see that the Weiner process inherits many of the same properties as our scaled symmetric random walk. Namely, independent increments with each one being distributed normally. With the Weiner process the increments are exactly normal instead of approximately normal (for large \(n\)) with the scaled symmetric random walk.
One way to think of the Weiner process is that each \(\omega\) is a path generated by a random experiment, for example, the random motion of a particle suspended in a fluid. At each infinitesimal point in time, it is perturbed randomly (distributed normally) into a different direction. In fact, this is the origin of the phenomenon by botanist Robert Brown (although the math describing it came after by several others including Einstein).
Another way to think about the random motion is using our analogy of coin tosses. \(\omega\) is still the outcome of an infinite sequence of coin tosses but instead of happening at each integer value of \(t\), they are happening "infinitely fast". This is essentially the result of taking our limit to infinity.
We can ask any question that we would usually ask about random variables to the Wiener process at a particular \(t\). The next example shows a few of them.
Example 5: Weiner Process
Suppose we wish to determine the probability that the Weiner process at \(t=0.25\) is between \(0\) and \(0.25\). Using our rigourous jargon, we would say that we want to determine the probability of the set \(A \in \mathcal{F}\) containing \(\omega \in \Omega\) satisfying \(0 \leq W(0.25) \leq 0.2\).
We know that each increment is normally distributed with expectation of \(0\) and variance of \(t_{i+1}-t_{i}\), so for the \([0, 0.25]\) increment, we have:
Thus, we are just asking the probability that a normal distribution takes on these values, which we can easily compute using the normal distribution density:
We also have the concept of filtrations for the Wiener process. It uses the same definition as we discussed previously except it also adds the condition that future increments are independent of any \(\mathcal{F_t}\). As we will see below, we will be using more complex adapted stochastic processes as integrands against a Wiener process integrator. This is why it's important to add this additional condition of independence for future increments. It's so the adapted stochastic process (with respect to the Wiener process filtration) can be properly integrated and cannot "see into the future".
2.4.3 Quadratic Variation of Wiener Process
We looked at the quadratic variation above for the scaled symmetric random walk and concluded that it accumulates quadratic variation one unit per time (i.e., quadratic variation is \(T\) for \([0, T]\)) regardless of the value of \(n\). We'll see that this is also true for the Wiener process but before we do, let's first appreciate why this is strange.
Let \(f(t)\) be a function defined on \([0, T]\). The quadratic variation of \(f\) up to \(T\) is
\begin{equation*} [f, f](T) = \lim_{||\Pi|| \to 0} \sum_{j=0}^{n-1}[f(t_{j+1}) - f(t_j)]^2 \tag{2.18} \end{equation*}for \(\Pi = \{t_0, t_1, \ldots, t_n\}\), \(0\leq t_1 \leq t_2 < \ldots < t_n = T\) and \(||\Pi|| = \max_{j=0,\ldots,n} (t_{j+1}-t_j)\).
This is basically the same idea that we discussed before: for infinitesimally small intervals, take the difference of the function for each interval, square them, and then sum them all up. Here we can have unevenly spaced partitions with the only condition being that the largest partition has to go to zero. This is called the mesh or norm of the partitions, which is similar to the formal definition of Riemannian integrals (even though many of us, like myself, didn't learn it this way). In any case, the idea is very similar to just having evenly spaced intervals that go to zero.
Now that we have Equation 2.18, let's see how it behaves on a function \(f(t)\) that has a continuous derivative: (recall the mean value theorem states that \(f'(c) = \frac{f(a) - f(b)}{b-a}\) for \(c \in (a,b)\) if \(f(x)\) is a continuous function with derivatives on the respective interval):
\begin{align*} [f, f](T) &= \lim_{||\Pi|| \to 0} \sum_{j=0}^{n-1}[f(t_{j+1}) - f(t_j)]^2 && \text{definition} \\ &= \lim_{||\Pi|| \to 0} \sum_{j=0}^{n-1}|f'(t_j^*)|^2 (t_{j+1} - t_j)^2 && \text{mean value theorem} \\ &\leq \lim_{||\Pi|| \to 0} ||\Pi|| \sum_{j=0}^{n-1}|f'(t_j^*)|^2 (t_{j+1} - t_j) \\ &= \big[\lim_{||\Pi|| \to 0} ||\Pi||\big] \big[\lim_{||\Pi|| \to 0} \sum_{j=0}^{n-1}|f'(t_j^*)|^2 (t_{j+1} - t_j)\big] && \text{limit product rule} \\ &= \big[\lim_{||\Pi|| \to 0} ||\Pi||\big] \int_0^T |f'(t)|^2 dt = 0&& f'(t) \text{ is continuous} \\ \tag{2.19} \end{align*}
So we can see that quadratic variation is not very important for most functions we are used to seeing i.e., ones with continuous derivatives. In cases where this is not true, we cannot use the mean value theorem to simplify quadratic variation and we potentially will get something that is non-zero.
For the Wiener process in particular, we do not have a continuous derivative and cannot use the mean value theorem as in Equation 2.19, so we end up with non-zero quadratic variation. To see this, let's take a look at the absolute value function \(f(t) = |t|\) in Figure 3. On the interval \((-2, 5)\), the slope between the two points is \(\frac{3}{7}\), but nowhere in this interval is the slope of the absolute value function \(\frac{3}{7}\) (it's either constant 1 or constant -1 or undefined).
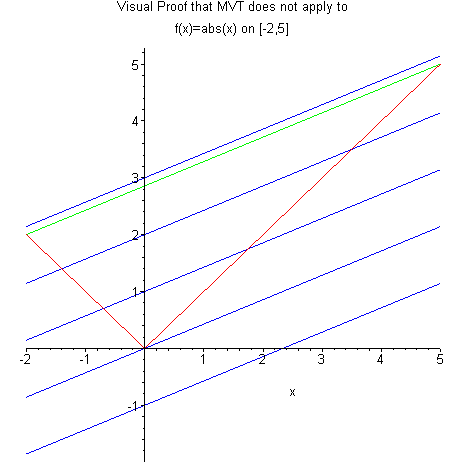
Figure 3: Mean value theorem does not apply on functions without derivatives (source)
Recall, this is a similar situation to what we had for the scaled symmetric random walk -- in between each of the discrete points, we used a linear interpolation. As we increase \(n\), this "pointy" behaviour persists and is inherited by the Wiener process where we no longer have a continuous derivative. Thus, we need to deal with this situation where we have a function that is continuous everywhere, but differentiable nowhere. This is one of the key reasons why we need stochastic calculus, otherwise we could just use the standard rules for calculus that we all know and love.
Theorem 1
For the Wiener process \(W\), the quadratic variation is \([W,W](T) = T\) for all \(T\geq 0\) almost surely.
Proof
Define the sampled quadratic variation for partition as above (Equation 2.18):
This quantity is a random variable since it depends on the particular "outcome" path of the Wiener process (recall quadratic variation is with respect to a particular realized path).
To prove the theorem, we need to show that the sampled quadratic variation converges to \(T\) as \(||\Pi|| \to 0\). This can be accomplished by showing \(E[Q_{\Pi}] = T\) and \(Var[Q_{\Pi}] = 0\), which says that we will converge to \(T\) regardless of the path taken.
We know that each increment in the Wiener process is independent, thus their sums are the sums of the respective means and variances of each increment. So given that we have:
We can easily compute \(E[Q_{\Pi}]\) as desired:
From here, we use the fact that the expected value of the fourth moment of a normal random variable with zero mean is three times its variance. Anticipating the quantity we'll need to compute the variance, we have:
Computing the variance of the quadratic variation for each increment:
From here, we can finally compute the variance:
As \(\lim_{||\Pi|| \to 0} Var[Q_\Pi] = 0\), therefore we have shown that \(\lim_{||\Pi|| \to 0} Q_\Pi = T\) as required.
The term almost surely is a technical term meaning with probability 1. This is another unintuitive idea when dealing with infinities. The theorem doesn't say that there are no paths with different quadratic variation, it only says those paths are negligible in size with respect to the infinite number of paths, and thus have probability zero.
Taking a step back, this is quite a profound result: if you take any realized path of the Wiener process, sum the infinitesimally small squared increments of that paths, it equals the length of the interval almost surely. In other words, the Wiener process accumulates quadratic variation at a rate of one unit per time.
This is perhaps surprising result because it can be any path. It doesn't matter how the "infinitely fast" coin flips land, the sum of the square increments will always approach the length of the interval. The fact that it's also non-zero is surprising too despite the path being continuous (but without a continuous derivative) as we discussed above.
We often will informally write:
To describe the accumulation of quadratic variation at one unit per time. However, this should not be interpreted to be true for each infinitesimally small increment. Recall each increment of \(W(t)\) is normally distributed, so the LHS of Equation 2.26 is actually distributed as the square of a normal distribution. We only get the result of Theorem 1 when we sum a large number of them (see [1] for more details).
We can also use this informal notation to describe a few other related concepts. The cross variation (Equation 2.27) and quadratic of variation for the time variable (Equation 2.28) respectively:
The quadratic variation for time can use the same definition from Equation 2.18 above, and the cross variation just uses two different function (\(W(t)\) and \(t\)) instead of the same function. Intuitively, both of these are zero because the time increment (\(\Pi\)) goes to zero in the limit by definition, thus so do these two variations. This can be shown more formally using similar arguments as the quadratic variation above (see [1] for more details).
2.4.4 First Passage Time for Wiener Process
We digress here to show a non-intuitive property of the Wiener process: it will eventually be equal to a given level \(m\).
Theorem 2
For \(m \in \mathbb{R}\), the first passage time \(\tau_m\) of the Wiener process to level \(m\) is finite almost surely, i.e., \(P(\tau_m < \infty) = 1\).
This basically says that the Wiener process is almost certain to reach whatever finite level within some finite time \(\tau_m\). Again, there is a possible realized path of the Wiener process that does not exceed a given level \(m\) but they collectively are so infinitesimally small that they are assigned probability 0 (almost surely). Working with infinities can be unintuitive.
2.5 The Relationship Between the Wiener Process and White Noise
The Wiener process can be characterized in several equivalent ways with the definition above being one of the most common. Another common way to define it is from the white noise we discussed in the motivation section. In this definition, the Wiener process is the definite integral of Gaussian white noise, or equivalently, Gaussian white noise is the derivative of the Wiener process:
To understand why this relationship is true, let's first define the derivative of a stochastic process from [4]:
A stochastic process \(X(t)\), \(t \in \mathbb{R}\), is said to be differentiable in quadratic mean with derivative \(X'(t)\) if
\begin{align*} \frac{X(t+h) - X(t)}{h} &\to X'(t) \\ E\big[(\frac{X(t+h) - X(t)}{h} - X'(t))^2 \big] &\to 0 \\ \tag{2.31} \end{align*}when \(h \to 0\).
We can see that the definition is basically the same as regular calculus except that we require the expectation to go to zero with a weaker squared convergence, which we'll see appear again in the next section.
From this definition, we can calculate the mean of the derivative of \(W(t)\) as:
Similarly, we can show a general property about the time correlation of a derivative of a stochastic process:
Thus we have shown that the time correlation of the derivative of a stochastic process is the mixed second-order partial derivative. Now all we have to do is evaluate it for the Wiener process.
First, assuming \(t_1 < t_2\) the Wiener process time correlation is given by (see this StackExchange answer for more details):
We get the same result if \(t_2 < t_1\), thus \(C_W(t_1, t_2) = \min(t_1, t_2)\). Now we have to figure out how to take the second order partial derivatives. The first partial derivative is easy as long as \(t_1 \neq t_2\) (see this answer on StackExchange):
where \(H(x)\) is the Heaviside step function. But we know the derivative of this step function is just the Dirac delta function (even with the missing point), so:
From Equation 2.32 and 2.36, we see we have the same statistics as the white noise we defined in the motivation section above in Equation 1.4. Since the mean is also zero, the covariance is equal to the time correlation too: \(Cov_{W'}(t_1, t_2) = C_{W'}(t_1, t_2)\)
Now all we have to show is that it is also normally distributed. By definition (given above) the Wiener stochastic process has derivative:
But since each increment of the Wiener process is normally distributed (and independent), the derivative from Equation 2.37 is also normally distributed since the difference of two independent normals is normally distributed. This implies the derivative of the Wiener process is a Gaussian process with zero mean and delta time correlation, which is the standard definition of Gaussian white noise. Thus, we have shown the relationship in Equation 2.29 / 2.30.
2.6 The Importance of the Wiener Process
One question that you might ask (especially after reading the next section) is why is there so much focus on the Wiener process? It turns out that the Wiener process is the only (up to a scaling factor and drift term) continuous process with stationary independent increments [5]. Let's be more precise.
A stochastic process is said to have independent increments if \(X(t) - X(s)\) is independent of \(\{X(u)\}_{u\leq s}\) for all \(s\leq t\). If the distribution of the increments don't depend on \(s\) or \(t\) directly (but can depend on \(t-s\)), then the increments are called stationary. This leads us to this important result:
Theorem 3
Any continuous real-valued process \(X\) with stationary independent increments can be written as:
where \(b, \sigma\) are constants.
Equation 2.38 is the generalized Wiener process that includes a potentially non-zero initial value \(X(0)\), deterministic drift term \(bt\), and scaling factor \(\sigma\).
The intuition behind Theorem 3 follows directly from the central limit theorem. For a given interval \([s, t]\), the value of \(X(t) - X(s)\) is the sum of infinitesimally small independent, identically distributed partitions, or in other words IID random variables (doesn't have to be normally distributed). Thus, we can apply the central limit theorem and get a normal distribution (under some mild conditions).
Processes with independent increments appear in many contexts. For example, the random displacement of a macro particle moving through a fluid caused by the random interactions with the fluid molecules is naturally modelled using the Wiener process. Similarly, the variability of the return of a stock price in a very short period of time is approximately the same regardless of the price, thus can also be modelled using a Wiener process. We'll look at both of these examples more closely later on in the post.
3 Stochastic Calculus
One of the main goals of stochastic calculus is to make sense of the following integral:
where \(X(t)\) and \(H(t)\) are two special types of stochastic processes. A few questions immediately come to mind:
What "thing" do we get out of the stochastic integral? This is pretty simple, it's another stochastic process, although it's not immediately clear that should be case, but rather something that becomes more obvious once we see the definition.
How do we deal with the limits of integration being in terms of time \(t\) but the integrand and integrator being stochastic processes with time index set \(t\)? We'll see below that the definition of the integral is conceptually not too different from a plain old Riemannian integral that we learn in regular calculus, but with some key differences due to the nature of the stochastic processes we use (e.g., Wiener process).
How do we deal with the case of a non-continuous derivative of the integrator (e.g., Wiener process), which manifests itself with non-zero quadratic variation? We'll see that this results in one of the big differences with regular calculus. Choices that didn't matter, suddenly matter, and the result produces different outputs from the usual integration operation.
All the depth we went into previously is about to pay off! We'll have to use all of those ideas in order to properly define Equation 3.1. We'll start with defining the simpler cases where \(X(t)\) is a Wiener process, and generalize it to be any Itô process, and then introduce the key result called Itô's lemma, a conceptual form of the chain rule, which will allow us to solve many more interesting problems.
3.1 Stochastic Integrals with Brownian Motion
To begin, we'll start with the simplest case when the integrator (\(dX(t)\) in Equation 3.1) is the Wiener process. For this simple case, we can define the integral as:
where \(t_j \leq s_j \leq t_{j+1}\), and \(||\Pi||\) is the mesh (or maximum partition) that goes to zero while the number of partitions goes to infinity like in Equation 2.18 (and standard Riemannian integrals).
From a high level, Equation 3.2 is not too different from our usual Riemannian integrals. However, we have to note that instead of having a \(dt\), we have a \(dW(s)\). This makes the results more volatile than a regular integral. Let's contrast the difference between approximating a regular and stochastic integral for a small step size \(\Delta t\) starting from \(t\):
\(R(t)\) changes more predictably than \(I(t)\) since we know that each increment changes by \(H(s)\Delta t\). Note that \(H(s)\) can still be a random (and \(R(t)\) can be random as well) but its change is multiplied by a deterministic \(\Delta t\). This is in contrast to \(I(t)\) which changes by \(W(t + \Delta t) - W(t)\). Recall that each increment of the Wiener process is independent and distributed normally with \(\mathcal{N}(0, \Delta t)\). Thus \(H(t)(W(t + \Delta t) - W(t))\) changes much more randomly and erratically because our increments follow an independent normal distribution versus just a \(\Delta t\). This is one of the key intuitions why we need to define a new type of calculus.
To ensure that the stochastic integral in Equation 3.2 is well defined, we need a few conditions, which I will just quickly summarize:
The choice of \(s_j\) is quite important (unlike regular integrals). The Itô integral uses \(s_j = t_j\), which is more common in finance; the Stratonovich integral uses \(s_j = \frac{(t_j + t_{j+1})}{2}\), which is more common in physics. We'll be using the Itô integral for most of this post, but will show the difference in the example below.
\(H(t)\) must be adapted to the same process as our integrator \(X(t)\), otherwise we would be allowing it to "see into the future". For most of our applications, this is a very reasonable assumption.
The integrand needs to have square-integrability: \(E[\int_0^T H^2(t)dt] < \infty\).
-
We ideally want to ensure that each sample point of the integrand \(H(s_j)\) from Equation 3.2 converges in the limit to \(H(s)\) with probability one (remember we're still working with stochastic processes here). That's a pretty strong condition, so we'll actually use a weaker squared convergence as:
\begin{equation*} \lim_{n \to \infty} E\big[\int_0^T |H_n(t) - H(t)|^2 dt\big] = 0 \tag{3.5} \end{equation*}where we define \(H_n(s) := H(t_j)\) for \(t_j \leq s < t_{j+1}\) i.e., it's the constant piece-wise approximation for \(H(t)\) using the left most point for the interval.
Example 6: A Simple Stochastic Integral in Two Ways
Let's work through the simple integral where the integrand and integrator are both the Wiener process:
First, we'll work through it using the Itô convention where \(s_j=t_j\):
The first term is just a telescoping sum, which has massive cancellation:
The second term you'll notice is precisely the quadratic variance from Theorem 1, which we knows equals the interval \(t\). Putting it together, we have:
We'll notice that this almost looks like the result from calculus i.e., \(\int x dx = \frac{x^2}{2}\), except with an extra term. As we saw above the extra term comes in precisely because we have non-zero quadratic variation. If the Wiener process had continuous differentiable paths, then we wouldn't need all this extra work with stochastic integrals.
Now let's look at what happens when we use the Stratonovich convention (using the \(\circ\) operator to denote it) with \(s_j = \frac{t_j + t_{j+1}}{2}\):
We use the fact that the half-sample quadratic variation is equal to \(\frac{t}{2}\) using a similar proof to Theorem 1.
What we see here is that the Stratonovich integral actually follows our regular rules of calculus more closely, which is the reason it's used in certain domains. However in many domains such as finance, it is not appropriate. This is because the integrand represents a decision we are making for a time interval \([t_j, t_{j+1}]\), such as a position in an asset, and we have to decide that before that interval starts, not mid-way through. That's analogous to deciding in the middle of the day that I should have actually bought more of a stock at the start of the day for a stock that went up in price.
3.1.1 Quadratic Variation of Stochastic Integrals with Brownian Motion
Let's look at the quadratic variation (or sum of squared incremental differences) along a particular path for the stochastic integral we just defined above, and a related property. Note: the "output" of the stochastic integral is a stochastic process.
Theorem 3
The quadratic variation accumulated up to time \(t\) by the Itô integral with the Wiener process (denoted by \(I\)) from Equation 3.2 is:
Theorem 4 (Itô isometry)
The Itô integral with the Wiener process from Equation 3.2 satisfies:
A couple things to notice. First, the quadratic variation is "scaled" by the underlying integrand \(H(t)\) as opposed to accumulating quadratic variation at one unit per time from the Wiener process.
Second, we start to see the difference between the path-dependent quantity of quadratic variation and variance. The former depends on the path taken by \(H(t)\) up to time \(t\). If it's large, then the quadratic variation will be large, and similarly small with small values. Variance on the other hand is a fixed quantity up to time \(t\) that is averaged over all paths and does not change (given the underlying distribution).
Finally, let's gain some intuition on the quadratic variation by utilizing the informal differential notation from Equation 2.26-2.28. We can re-write our stochastic integral from Equation 3.2:
as:
Equation 3.13 is the integral form while Equation 3.14 is the differential form, and they have identical meaning.
The differential form is a bit easier to understand intuitively. We can see that it matches the approximation (Equation 3.4) that we discussed in the previous subsection. Using this differential notation and the informal notation we defined above in Equation 2.26-2.28, we can "calculate" the quadratic variation as:
using the fact that the quadratic variation for the Wiener process accumulates at one unit per time (\(dW(t)dW(t) = dt\)) from Theorem 1. We'll utilize this differential notation more in the following subsections as we move into stochastic differential equations.
3.2 Itô Processes and Integrals
In the previous subsections, we only allowed integrators that were Wiener processes but we'd like to extend that to a more general class of stochastic processes called Itô processes 2:
Let \(W(t)\), \(t\geq 0\), be a Wiener process with an associated filtration \(\mathcal{F}(t)\). An Itô process is a stochastic process of the form:
\begin{equation*} X(t) = X(0) + \int_0^t \mu(s) ds + \int_0^t \sigma(s) dW(s) \tag{3.16} \end{equation*}where \(X(0)\) is nonrandom and \(\sigma(s)\) and \(\mu(s)\) are adapted stochastic processes.
Equation 3.16 can also be written in its more natural (informal) differential form:
A large class of stochastic processes are Itô processes. In fact, any stochastic process that is square integrable measurable with respect to a filtration generated by a Wiener process can be represented by Equation 3.16 (see the martingale representation theorem). Thus, many different types of stochastic processes that we practically care about are Itô processes.
Using our differential notation, we can take Equation 3.17 and take the expectation and variance to get more insight:
In Equation 3.18, \(\sigma(t)\) and \(dW(t)\) are independent because \(\sigma(t)\) is adapted to \(W(t)\), thus the \(dW(t)\) increment is in the "future" of the current value of \(\sigma(t)\). This reasoning only works because of the choice of the \(s_j=t_j\) in Equation 3.2 for the Itô integral.
In fact, this result actually holds if we convert to our integral notation:
So the notation of using \(\mu\) and \(\sigma\) makes more sense. The regular time integral contributes to the mean of the Itô process, while the stochastic integral contributes to the variance. We'll see how we can practically manipulate them in the next section.
Lastly as with our other processes, we would like to know its quadratic variation. Informally we can compute quadratic variation as:
which is essentially the same computation we used in Equation 3.19 above (and the same as the variance). In fact, we get the same result as with the simpler Wiener process where we accumulate quadratic variation with \(H^2(t)\) per unit time. The reason is that the cross variation (Equation 2.27) and time quadratic variation (Equation 2.28) are zero and don't contribute to the final expression.
Finally, let's see how to compute an integral of an Itô process \(X(t)\) using our informal differential notation:
As we can see, it's just a sum of a simple Wiener process stochastic integral and a regular time integral.
Example 7: A Simple Itô Integral
Starting with our Itô process:
where \(A, B\) are constant. Now calculate a simple integral using it as the integrator:
where \(C\) is constant. From there, we can see that the mean and variance of this process can be calculated in a straight forward manner since \(W(t)\) is the only random component:
Which is the same result as if we just directly computed Equation 3.20/3.21. The final result is a simple stochastic process that is essentially a Wiener process but that drifts up by \(AC\) over time.
3.3 Itô's Lemma
Although many stochastic processes can be written as Itô processes, often times the process under consideration is not in the form of Equation 3.16/3.17. A common situation is where our target stochastic process \(Y(t)\) is a deterministic function \(f(\cdot)\) of a simpler Itô process \(X(t)\):
In these situations, we'll want a method to simplify this so we can get it into the simpler form of Equation 3.16/3.17 with a single \(dt\) and a single \(dW(s)\) term. This technique is known as Itô's lemma.
Itô's Lemma
Let \(X(t)\) be an Itô process as described in Equation 3.16/3.17, and let \(f(t, x)\) be a function for which the partial derivatives \(\frac{\partial f}{\partial t}, \frac{\partial f}{\partial x}, \frac{\partial^2 f}{\partial x^2}\) are defined and continuous. Then for \(T\geq 0\):
Or using differential notation, we can re-write the first equation more simply as:
Informal Proof
Expand \(f(t, x)\) as a Taylor series:
Substitute \(X(t)\) for \(x\) and \(\mu(t)dt + \sigma(t)dW(s)\) for \(dx\):
As you can see, we can re-write the above stochastic process from Equation 3.28 in terms of a single \(dt\) and single \(dW(s)\) term (using differential notation). This can be thought of as a form of the chain rule for total derivatives, except now that we have a non-zero quadratic variation, we need to include the extra second order term involving \(dW(s)dW(s)\).
Itô's lemma is an incredibly important result because most applications of stochastic calculus are "little more than repeated use of this formula in a variety of situations" [1]. In fact, based on what I can tell, many introductory courses to stochastic calculus skip over a lot of the theoretical material and simply just jump directly into applications of Itô's lemma because that's mostly what you need.
Example 7: Itô's Lemma
Given the Itô process \(X(t)\) as given by Equation 3.16, consider the stochastic process \(Y(t)\):
Using Itô's Lemma, we can re-write \(Y(t)\) as (in the differential form since it's cleaner):
Which specifies \(Y(t)\) in a simpler form of just a \(dt\) and \(dW\) term.
3.4 Stochastic Differential Equations
One of the most common problems we want to use stochastic calculus for is solving stochastic differential equations (SDE). Similar to their non-stochastic counterpart, they appear in many different phenomenon (a couple of which we will see in the next section) and are usually very natural to write, but not necessarily to easy solve.
Starting with the definition:
A stochastic differential equation is an equation of the form:
\begin{align*} dX(t) &= \mu(t, X(t))dt + \sigma(t, X(t)) dW(t) && \text{differential form}\tag{3.35} \\ X(T) &= X(t) + \int_t^T \mu(u, X(u))du + \int_t^T \sigma(u, X(u)) dW(u) && \text{integral form} \tag{3.36} \end{align*}where \(\mu(t, x)\) and \(\sigma(t, x)\) are given functions called the drift and diffusion respectively. Additionally, we are given an initial condition \(X(t) = x\) for \(t\geq 0\). The problem is to then find the stochastic process \(X(T)\) for \(T\geq t\).
Notice that \(X(t)\) appears on both sides making it difficult to solve for explicitly. A nice property though is that under mild conditions on \(\mu(t, x)\) and \(\sigma(t, x)\), there exists a unique process \(X(T)\) that satisfies the above. As you might also guess, one-dimensional, linear SDEs can be solved for explicitly.
SDEs can add similar complexities as their non-stochastic counterparts such as non-linearities, systems of SDEs, and multidimensional SDEs (with multiple associated Wiener processes) etc. Generally, SDEs won't have explicit closed form solutions so you'll have to use numerical methods to solve them.
The two popular methods are Monte Carlo simulation and numerically solving a partial differential equation (PDE). Roughly, Monte Carlo simulation for differential equations involve simulating many different paths of the underlying process and using these paths to compute the associated statistics (e.g., mean, variance etc.). Given enough paths (and associated time), you generally can get as accurate as you like.
The other method is to numerically solve a PDE. An SDE can be recast to as a PDE problem (at least in finance applications, not sure about others), and from the PDEs you can use the plethora of numerical methods to solve them. How both of these methods work is beyond the scope of this post (and how far I wanted to dig into this subject), but there is a lot of literature online about it.
4 Applications of Stochastic Calculus
(Note: In this section, we'll forgo the explicit parameterization of the stochastic processes to simplify the notation.)
4.1 Black-Scholes-Merton Model for Options Pricing
The rigorous math to get to the Black-Scholes-Merton model for options pricing is quite in depth so instead I'll just present a quick overview of some of the main concepts and intuition (following [6] closely). See [6] for a lighter but more intuitive treatment, and [1] for all the gory details.
4.1.1 The Process for a Stock Price
Stock prices are probably one of the most natural places where one would think about using stochastic processes. We might be tempted to directly use an Itô process with constant \(\mu\) and \(\sigma\). However, this translates to a linear growth in the stock price, which isn't quite right. Instead, investors are typically expecting the same percent return regardless of the current price vs. fixed linear growth. For example, if a stock's price is expected to grow at 10%, it should grow at that rate regardless of whether the price is 10 or 100. The naturally leads to this differential equation for stock price \(S\) and constant return \(\mu\) (a pretty big assumption):
The change in growth of the stock price (\(dS\)) is equal to the percent return of the current price (\(\mu S dt\)). This yields the solution at time \(t\) by dividing by \(S\) and integrating both sides:
Of course, this simplistic model has no random component. We would expect that the return is uncertain over a time period. A (perhaps) reasonable assumption to make is that for small time periods, the variability in the return is the same regardless of the stock price. That is, we are similarly unsure (as a percent of the stock) of the returns whether it's at 10 or 100. Using a Wiener process, we can add this assumption to Equation 4.1 as:
This results in a stochastic differential equation called geometric Brownian motion (GBM).
Fortunately, GBM has a closed form solution that we can derive by using Itô's lemma on \(f(s) = \log s\):
From that, we know the \(\log S\) process between increment \([0, t]\) is normally distributed with mean \((\mu - \frac{\sigma^2}{2})t\) (due to non-zero mean) and variance \(\sigma^2t\) telling us that:
Meaning \(S\) is log-normally distributed with the above statistics.
4.1.2 Black-Scholes-Merton Differential Equation
The BSM model is probably the most famous equation in quantitative finance, but it actually is quite complex to derive requiring all the stochastic calculus that we have covered so far. At the heart of the model is the BSM differential equation, which we will presently derive and discuss.
The first thing to understand is the "no arbitrage" condition. In the case of a financial derivative (e.g., call or put option) and the underlying stock, the price of the derivative should never allow one to make a portfolio of the two such that you are guaranteed to make money i.e., arbitrage. In this theoretical portfolio you can be "long", or buying and owning the financial security, or "short", owing the financial security but not owning it (implemented by borrowing the security, selling it, buying it at some later date, and returning the borrowed security). A theoretical "short" is essentially the opposite of buying and owning the asset where you benefit if the asset goes down.
To build this no arbitrage or "riskless" portfolio, we will want to go long/short the underlying stock and go short/long the derivative in exact proportion to the relative change in the asset prices of the two. This proportion between the two only exists for a short period of time under that exact condition, and will need to be rebalanced as market conditions change.
The other key idea is that once you have a "riskless" portfolio set up, it should return the "risk free" rate (within the short period of time the balance is maintained). The risk free rate is an asset that is virtually guaranteed to receive that given rate (think: a savings account, or more commonly a treasury bond). With these few conditions and some additional idealized assumptions (e.g., stock prices follow the model we developed, no transaction costs, no dividends, perfect "shorting" etc.), we can formulate the BSM differential equation.
Translating the above into concrete equations, we begin by assuming that stock prices of a security follow geometric Brownian motion from Equation 4.3:
An option on that security is some function \(f(S, t)\) of the current stock price \(S\) and the time \(t\), using Itô's Lemma we get:
Equations 4.6/4.7 describe infinitesimal changes in (a) the underlying stock (\(dS\)), and (b) the change in the underlying financial derivative (\(df\)). Notice the Wiener process associated with both is the same because \(f\) is derived from \(S\), which can be seen in the derivation of Itô's Lemma.
With these two equations, we now have SDEs for both the stock price \(S\) and the price of an option \(f(S, t)\). Our goal is to select a portfolio of the two (at a given time instant and price \(S\)) that doesn't change regardless of the random fluctuations in price of the underlying stock. This can be accomplished by ensuring that the stochastic components (\(dW\) terms in each SDE) cancel out. Since the \(dW\) terms are the only source of randomness, when they are cancelled we can derive an expression for the portfolio that deterministically changes with time.
Cancelling the stochastic terms is done simply by equating the two \(dW\) terms in Equations 4.6 and 4.7, which results in taking proportions of \(-1\) of the financial derivative and \(\frac{\partial f}{\partial S}\) shares of the underlying stock. In other words, the portfolio is short one derivative and long \(\frac{\partial f}{\partial S}\) shares. Defining our portfolio value as \(\Pi\), we get:
Taking the differentials, applying Itô's lemma, and plugging in Equation 4.6/4.7:
By construction (with our assumptions), \(\Pi\) is a riskless portfolio (at time instant \(t\)) that deterministically changes with \(t\). The assumption of a no arbitrage situation implies that this portfolio must make the risk free rate. If this portfolio earns more than the risk free rate you can just borrow money at the risk free rate and earn the difference between the two. If it earns less than the risk free rate then you can just short the portfolio (and pay the associated lower interest rate) and buy risk free securities and make the difference.
From this, we expect \(\Pi\) to earn the risk free rate for the infinitesimal time in which our portfolio is perfectly balanced. Using Equation 4.9 we can construct an SDE:
Equation 4.10 defines the Black-Scholes-Merton differential equation. Notice that this is a deterministic differential equation in \(f(S, t)\) because we have cancelled away the stochastic Wiener process and \(S, t\) are given with respect to \(f(S, t)\). It also has many solutions corresponding to the boundary conditions placed on \(f(S, t)\). For example, European call and put options have these associated boundary conditions for strike price \(K\) and expiry time \(T\):
In other words, when the call option contract expires, it is worth precisely the difference between the stock price and strike price or zero if negative (similarly in reverse for put options).
Solving this differential equation with these boundary conditions results in the most famous formulas that you'll find when searching for BSM (see here for more details). I won't go into all the details since that's not the focus of this post, but the fact that it has a closed form solution is a big plus. There are many more complex quantitative finance models that do not have closed form solutions, and even ones that go beyond Itô processes (see Jump Processes). These models require approximate solutions as discussed in section 3.4.
4.2 Langevin Equation
A Langevin equation is a well known stochastic differential equation that describes how a system evolves when subjected to a combination of deterministic and fluctuating forces. The original equation was developed well before stochastic calculus was discovered in the context of the apparent random movement of a particle through a fluid, which describes the physical phenomenon of Brownian motion. Since the Wiener process and Brownian motion are so related, they are sometimes used interchangeably to describe the underlying stochastic process.
Many people contributed to the discovery of Brownian motion (including Einstein) but the stochastic differential equation was derived several years after by Langevin (hence the name) in 1908. Interestingly, since Langevin did not approach his stochastic differential equation with much rigour (by mathematician standards), this gave rise to the field of stochastic analysis to answer some of the issues with Langevin's approach.
In this section, I'm going to give a brief overview of the Langevin equation in the context of Brownian motion, glossing over many of the usual analyses one would do in a physics class. Additionally, I'm going to approach it using Itô calculus, which is not the typical approach (not the one originally used). Finally, I'll briefly mention its relationship to a financial application.
4.2.1 Brownian Motion and the Langevin Equation
The original Langevin equation describes the random movement of a (usually much larger) particle suspended in a fluid due to collisions with the molecules of the fluid:
where \(m\) is the mass, \(\bf v_t\) is the velocity, \(\frac{d{\bf v_t}}{dt}\) is the acceleration (the time derivative of velocity), and \(\bf \eta\) is a white noise term with zero mean and flat frequency spectrum (the same one we discussed in Section 2.5). The easiest way to interpret this equation is using Newton's second law of motion: the net force on an object is equal to its mass times acceleration (\(F_{net} = ma\)). The right hand side is the net force, and the left hand side is the product of mass and acceleration.
Breaking it down further, there are two types of forces acting on our particle suspended in a fluid: (a) a drag force of the fluid that is proportional to its velocity (think something analogous to air resistance), and (b) a noise term representing the effect of random collisions with the small fluid molecules. This is a bit strange because we're combining the microscopic (drag force acting on the particle) with a seemingly macroscopic average from the noise. This needs a bit of explanation.
The noise term is an approximation of sorts. For any given time instant, there (theoretically) are specific molecules colliding with our target particle so why are we considering this noise term \(\bf \eta\)? Besides simplifying the math, the justification is that it is a good approximation for the average force within a small time instant because of the scale of our observations. Our instruments do not have infinite precision and only measure finitely small time intervals, this means the resulting observations are really an average over these small finite time intervals and look a lot like the white noise term in Equation 4.13. So while not exact (like any model), it provides a pretty good approximation for this phenomenon (and many others with some variations on the basic equation).
Interestingly, the noise term was not precisely defined (i.e., mathematically rigorous) when Langevin wrote his original equations. However with the advent of stochastic calculus, we can write an equivalent stochastic differential equation, which is often referred to as the Ornstein-Uhlenbeck process as:
where \(\theta, \sigma\) are constants, and assume \(\eta(t) = \frac{dW}{dt}\). As an aside, technically, the Wiener process is nowhere differentiable, so \(\frac{dW}{dt}\) does not have a precise meaning, which is why we rarely write it in this form and instead use the differential form of Equation 4.14.
Equation 4.14 is complicated by the fact that we have our target process \(v_t\) mixed in with differentials and non-differentials i.e., a stochastic differential equation. Since this is a relatively simple SDE, we can use similar techniques to solving their non-stochastic counterparts along with Itô's lemma to compute the differential.
Without going into all of the reasoning behind it, we'll start with the function \(f(t, v_t) = v_t e^{\theta t}\), write down its differential and its Taylor expansion similar to our (informal) derivation of Itô's lemma:
Which shows the general solution to our stochastic differential equation. We can characterize this stochastic process by evaluating its mean and variance. First, we use the fact that an Itô integral of a deterministic integrand is normally distributed, thus the second term in Equation 4.15 has zero mean, and so (assuming a non-random initial velocity \(v_0\)):
Showing the average velocity vanishes relatively quickly over time. Next, we can compute the variance using Itô's isometry (Theorem 4 above):
From the mean and variance, and the fact the integrator in \(v_t\) is normally distributed, we can infer that the stochastic process is one with a scaled and shifted Wiener process:
Similarly, we can compute the displacement \(x_t\) by integrating \(v_t\) with respect to time:
I won't expand the last time integral, but you can calculate it using the explanation in this StackExchange answer, which has a zero mean. Thus, the average displacement asymptotes to \(\frac{v_0}{\theta}\) over time. See the following Wikipedia article for more details on the physics of it all.
5 Conclusion
Well I did it again! I went down a rabbit hole, and before I knew it I was in over my head on this topic. In a lot of ways it's nice learning on your own time because you can meander. I will say I had no idea what I was getting myself into when I started to write this post. Little did I know I would have to learn more about measure theoretic probability theory (something that was never a priority for me), nor that stochastic calculus needed so technical depth in order to intuitively understand the underlying math (vs. just symbol manipulation). In any case, I'm glad I dug into it but I'll be happy when I can get back on track to more standard ML topics. Until next time!
6 References
Wikipedia: Stochastic Processes, Adapted Stochastic Process
[1] Steven E. Shreve, "Stochastic Calculus for Finance II: Continuous Time Models", Springer, 2004.
[2] Michael Kozdron, "Introduction to Stochastic Processes Notes", Stats 862, University of Regina, 2006.
[3] "Introduction to Stochastic Differential Equations", Harvard, 2007.
[4] Maria Sandsten, "Differentiation of stationary stochastic processes", 2020.
[5] George Lowther, Continuous Processes with Independent Increments
[6] John C. Hull, "Options, Futures, and Other Derivatives", Pearson, 2018.
7 Appendix A: Event Space and Probability Measure for a Bernoulli Process
As mentioned the sample space for the Bernoulli process is all infinite sequences of heads and tails: \(\Omega = \{ (a_n)_1^{\infty} : a_n \in {H, T} \}\). The first thing to mention about this sample space is that it is uncountable, which basically means it is "larger" than the natural numbers. Reasoning in infinities is quite unnatural but the two frequent "infinities" that usually pop up are sets that have the same cardinality ("size") as (a) the natural numbers, and (b) the real numbers. Our sample space has the same cardinality as the latter. Cantor's original diagonalization argument actually used a variation of this sample space (with \(\{0, 1\}\)'s), and the proof is relatively intuitive. In any case, this complicates things because a lot of our intuition falls apart when we work with infinites, and especially with infinities that have the cardinality of the real numbers.
(This construction was taken from [1], which is a dense, but informative reference for all the topics in this post.)
Now we will construct the event space (\(\sigma\)-algebra) and probability measure for the Bernoulli process. We'll do it iteratively. First, let's define \(P(\emptyset) = 0\) and \(P(\Omega) = 1\), and the corresponding (trivial) event space:
Notice that \(\mathcal{F}_0\) is a \(\sigma\)-algebra. Next, let's define two sets:
And set the intuitive definition of the corresponding probability measure: \(P(A_H) = p\) and \(P(A_T) = 1-p\). That is, the probability of seeing an H on the first toss is \(p\), otherwise \(1-p\). Since these two sets are compliments of each other (\(A_H = A_T^c\)), this defines another \(\sigma\)-algebra:
We can repeat this process again but for the first two tosses, define sets:
Similarly, we can extend our probability measure with the definition we would expect: \(P(A_{HH}) = p^2, P(A_{HT}) = p(1-p), P(A_{TH}) = p(1-p), P(A_{TT}) = (1-p)^2\). Now we have to do a bit more analysis, but if one works out every possible set we can create either from compliments or unions of any of the above sets, we'll find that we have 16 in total. For each one of them, we can compute its probability measure by using one of the above definitions or by the fact that \(P(A) = 1-P(A)\) or \(P\big(\bigcup_{n=1}^{N} A_N \big) = \sum_{n=1}^{N} P(A_N)\) if the sets are disjoint. These 16 sets define our next \(\sigma\)-algebra:
As you can imagine, we can continue this process and define the probability (and associated \(\sigma\)-algebra) for every set in terms of finitely many tosses. Let's call this set \(\mathcal{F}_\infty\), which contains all of the sets that can be described by any number of finitely many coin tosses using the procedure above, and then adding in all the other ones using the compliment or union operator. This turns out to be precisely the \(\sigma\)-algebra of the Bernoulli process. And by the construction, we also have defined the associated probability measure for each one of the events in \(\mathcal{F}_\infty\).
Now we could leave it there, but let's take a look at the non-intuitive things that go on when we work with infinities. This definition implicitly includes sequences that weren't explicitly defined by us, for example, the sequence of all heads: \(H, H, H, H, \ldots\). But we can see this sequence is included in \(A_H, A_{HH}, A_{HHH}, \ldots\). Further, we have:
so this implies the probability of \(P(\text{sequence of all heads}) = 0\). This illustrates an important non-intuitive result: all (infinite) sequences in our sample space have probability \(0\). Importantly, it doesn't mean they can never occur, just that they occur "infinitesimally". Similarly, the complement ("sequences of at least one tails") happens with probability \(1\). Mathematicians have a name for this probability equals to \(1\) event: almost surely. So any infinite sequence of coin flips almost surely has at least one tail. For finite event spaces, there is not difference between surely (always happens) and almost surely.
This definition also includes sets of sequences that cannot be easily defined such as:
where \(H_n\) denotes the number of heads in the \(n\) tosses. This can be implicitly constructed by taking (countably infinite) unions and intersections of sets that we have defined in our \(A_\ldots\) event space. See Example 1.1.4 from [1] for more details.
Finally, although it may seem that we will have defined every subset of our sample space, there does exist sequences that are not in \(\mathcal{F}_\infty\). But it's extremely hard to produce such a set (and don't ask me how :p).
- 1
-
I'm conveniently leaving out references to Lebesgue integrals (among other things) to not overcomplicate the topic. They are quite important and are needed to work properly with random variables where you need to integrate over a set.
- 2
-
In fact, we can admit a larger class of integrators for stochastic integrals called semimartingales, but for our purposes Itô processes will do just fine.